Comprehensive Handbook of Psychological Assessment
Volume 2: Personality Assessment
Comprehensive Handbook of Psychological Assessment, Volume 2: Personality Assessment Mark J. Hilsenroth (Editor), Daniel L. Segal (Editor), Michel Hersen (Editor-in-Chief) ISBN: 978-0-471-41612-8
September 2003
Table of Contents
Part Three: Overview, Conceptual, and Empirical Foundations
23 Projective Assessment of Personality and Psychopathology: An Overview 283 Mark J. Hilsenroth
24 Projective Tests: The Nature of the Task 297 Martin Leichtman
25 The Reliability and Validity of the Rorschach and Thematic Apperception Test (TAT) Compared To Other Psychological and Medical Procedures: An Analysis of Systematically Gathered Evidence 315 Gregory J. Meyer
CHAPTER 23 Projective Assessment of Personality and Psychopathology: An Overview
MARK J. HILSENROTH
HISTORICAL, THEORETICAL, AND PSYCHOMETRIC OVERVIEW 283 SPECIFIC INSTRUMENTS 286 SPECIFIC CONTENT AREAS 288
HISTORICAL, THEORETICAL, AND PSYCHOMETRIC OVERVIEW
Projective methods of personality assessment provide the clinician with a window through which to understand an individual by the analysis of responses to ambiguous or vague stimuli. These methods are generally unstructured and also call on the individual to create the data from his or her personal experience. An individual’s response(s) to these stimuli can reflect internal needs, emotions, past experiences, thought processes, relational patterns, and various aspects of behavior. Moreover, projective methods involve the presentation of a stimulus designed to evoke highly individualized meaning and organization. No limits on response are arbitrarily set, but rather, the individual is encouraged to explore an infinite range of possibilities in relating his or her private world of meanings, significance, affect, and organization (Frank, 1939).
It will suffice to say that while the instruments may differ, the results of these methods provide ready access to a variety of rich conscious and unconscious material. An important SPECIAL POPULATIONS AND SETTINGS 290 APPLICATIONS FOR CHILDREN AND ADOLESCENTS 292 CONCLUSION AND FUTURE PERSPECTIVES 292 REFERENCES 293
aspect of projective stimuli is their ability to provide information about thoughts, actions, and emotions. Also, the process of generating associations across different levels of meaning can aid in understanding an individual’s cognitive structures, the elements of which may often be disparate. The responses to these stimuli can also be a vehicle for understanding how someone experiences his or her world and conveys those experiences to others. These responses occur as a representation, through various mediums, of an individual’s personal experience such as narratives (i.e., storytelling) and the perception of visual images. The manner by which people create images and organize language, affective expressions, or perceptions is seen to be highly personal. These modes of responding can reveal patterns of that individual’s thought, associations, and experiences. It is in this capacity of exploring perceptual acuity, as well as interpersonal and affective themes, that the interpretation of projective material has been most utilized by clinicians in the past.
Many clinicians who utilize these free response or unstructured methods of assessment have expanded upon the initial theoretical conceptualization of this “projective response process” beyond a psychoanalytic paradigm to include ego psychology (Bellak & Abrams, 1997), constructivism (Raskin, 2001), perceptual-cognitive style (Exner, 1989, 1991, 1996), experiential factors (Lerner, 1992; Schachtel, 1966), explicit and implicit processes (McClelland, Koestner, & Weinberger, 1989), as well as process-dissociation (Bornstein, 2002) perspectives. The plurality of different theoretical perspectives from which to understand projective material is a significant benefit for those who would use these techniques.
This section begins with one such chapter by Leichtman that provides a compelling conceptualization of projective tasks. Leichtman’s chapter (Chapter 24) reviews traditional conceptions of the projective task and their limitations. First, Leichtman presents evidence for an alternative theory centering on the concept of representation and explores the roles of four key components in this response process. Second, he discusses the representational act (i.e., the sense of self, the audience, the use of the symbolic medium, and the referent) in the test response process. Finally, he concludes with an examination of the way in which this conception of the task provides a framework for understanding what unites projective instruments as a class, what differentiates them from one another, how their interpretation has been approached, and what are their inherent strengths and drawbacks.
A second important issue related to the theoretical conceptualization of these tests is their place in a multimethod assessment paradigm. Often, psychological assessment occurs along one modality, which limits application of results and restricts the extent to which data can be generalized to both clinical and research applications. In any psychological assessment, one needs to allow for problems of disorder differentiation, comorbidity, sampling from a range of different severities, symptom overlap, and complexity of that individual. The importance of a multitrait-multimethod approach to assessment has been stressed by a number of different authors (Campbell & Fiske, 1959; Jackson, 1971; Leary, 1957; Rapaport, Gill, & Schafer, 1945). Implicit in this approach is the idea that individuals are multidimensional beings who vary not only from one another but also in the way others view them (social perception), the way they view themselves (self-perception), and the ways in which underlying dynamics will influence their behavior (motivation/meaning/fantasy/ ideals). Such an approach presents clinicians and researchers with the responsibility to sample from each domain of functioning. This form of assessment may aid clinicians in obtaining a comprehensive understanding of an individual rather than focusing on just one facet of behavior. Also, various forms of Diagnostic and Statistical Manual of Mental Disorders (4th ed. [DSM-IV]; American Psychiatric Association
[APA], 1994) Axis I and II psychopathology have frequently been viewed as multidimensional and, therefore, a single score on any one measure may be far less optimal than an assessment process that provides information concerning the multiple aspects of a given syndrome (i.e. narcissistic pathology reflected in grandiosity, need for mirroring or admiration, narcissistic rage, entitlement, etc.). It seems prudent to encourage clinicians and researchers alike to employ multiple methods of assessing various forms of psychopathology and to utilize this information in a systematic and theoretically consistent fashion. The goal of this approach to diagnosis is to connect both the surface (readily apparent in behaviors) and deeper (intrapsychic) manifestations of any disorder in a conceptual manner, in order to generate clinical and dynamic signs that may be used reliably for differential diagnosis.
One of the issues related to this need for a multimethod psychological assessment faced by applied clinicians on a daily basis is what many in social and personality psychology have come to call self-report bias. A substantial body of experimental research has demonstrated that individuals exhibit a defensive bias when asked to self-report aspects of their personality or psychopathology. For example, individual differences in self-serving biases have been demonstrated in relation to attributions, self-descriptions, inferences, personality traits, and avoidance of negative affect (Block, 1995; Colvin, Block, & Funder, 1995; Dozier & Kobak, 1992; Funder, 1997; John & Robins, 1994; McClelland et al., 1989; Ozer, 1999; Shedler, Mayman, & Manis, 1993; Viglione, 1999; Weinberger, 1995). The presence and importance of intrapsychic, unconscious, implicit, automatic, private, or internal personality characteristics suggest that projective test variables may prove to be very useful when employed in tandem with other methods of assessment that are designed to assess more overt, direct, conscious, or behavioral expressions of psychopathology.
An assessment using measures that evaluate both intrapsychic as well as interpersonal and behavioral aspects of personality is optimal and provides clinicians with a richer understanding of individuals. This multidimensional assessment may be especially salient given that self-report inventories concerning the assessment of Axis I and Axis II tend to be more direct (i.e., obvious) in identifying symptoms and therefore are susceptible to malingered or defensive responses. Moreover, many clinical patients (i.e., patients with schizophrenia, delusional disorder, or personality disorder) are particularly unable to view themselves in a realistic manner. Interviews may allow for greater flexibility in the assessment of personality and psychopathology because clinical judgment may be necessary to determine or clarify whether the diagnostic aspects of a patient’s behavior are present (e.g., DSM-IV narcissistic personality disorder [NPD] Criterion 9: Arrogant and haughty behaviors). While interviews allow for the clinical observation of behavior, one has to wonder if this same criticism might also apply, at least in part, to semistructured interviews. Additionally, interviews have limitations of which clinicians should be well aware. Past research has indicated that clinicians may underestimate or minimize coexisting syndromes once the presence of one or two Axis II disorders has been recognized (Widiger & Frances, 1987). Unlike self-report inventories, which may include indices that detect intentional response dissimulation (faking), exaggeration of symptoms, random responding, acquiescence, or denial, clinical interviewers may be susceptible to active attempts at malingering. Assessment of Axis I and Axis II criteria may be difficult through direct inquiry and, therefore, it is questionable whether many patients would admit that they are, for example, egocentric, self-indulgent, inconsiderate, or interpersonally exploitive.
Perhaps because the scoring and interpretation of responses to projective techniques can be perceived by those unfamiliar or untrained in their use as less obvious or directly related to salient clinical issues, these methods have at various times come under harsh criticism (Dawes, 1994; Eysenck, 1959; Jensen, 1965; Lilienfeld, Wood, & Garb, 2000; Peterson, 1995; Wood, Nezworski, & Stejskal, 1996). In fact, some psychologists have promulgated such unrealistic clinical utility criteria for projective assessment instruments (Hunsley & Bailey, 1999, 2001) that the unbiased implementation of such standards across various methods of psychological evaluation would result in abandoning all testing, interviews, and observation for assessment. A subsequent extension of these criticisms has been a series of unrealistic calls for a moratorium on the use of some instruments (Garb, 1999; Garb, Florio, & Grove, 1998; Garb, Wood, Nezworski, Grove, & Stejskal, 2001). However, these recent criticisms are clearly contradicted by empirical findings; are flawed by the use of methodological double standards; and suffer from confirmatory bias and incomplete coverage of the literature. In addition, the critics fail to integrate positive contributions that have specifically addressed earlier criticisms and, most figural, they present no original data to support their positions (see Meyer, 1997a, 1997b, 2000, 2001; W. Perry, 2001; Viglione & Hilsenroth, 2001). Finally, these attempts to criticize and limit projective assessment occur in direct contradiction to recent evidence from clinical training, practice, and research (Bornstein, 1996, 1999; Camara, Nathan, & Puente, 2000; Clemence & Handler, 2001; Eisman et al., 2000; Hiller, Rosenthal, Bornstein, Berry, & Brunell-Neuleib, 1999; Meyer & Archer, 2001; Meyer et al., 2001; Meyer et al., 2002; Rosenthal, Hiller, Bornstein, Berry, & Brunell-Neuleib, 2001; Stedman, Hatch, & Schoenfeld, 2000; Viglione, 1999; Viglione & Hilsenroth, 2001; Weiner, 1996, 2001).
In the most recent analysis of extant validity data, Meyer and Archer (2001) provide a definitive response regarding the clinical utility of one projective technique, the Rorschach (Rorschach, 1921/1942), within the context of other psychological assessment instruments. After providing extensive validity data comparing the Rorschach with both intelligence (i.e., Wechsler Adult Intelligence Scale [WAIS]; Wechsler, 1997) and self-report measures of personality (i.e., Minnesota Multiphasic Personality Inventory [MMPI]/MMPI-2; Butcher, Dahlstrom, Graham, Tellegen, & Kaemmer, 1989) these authors offer the explicit conclusion that “there is no reason for the Rorschach to be singled out for particular criticism or specific praise. It produces reasonable validity, roughly on par with other commonly used tests” (pp. 491–492). Meyer and Archer (2001) further note that validity is always conditional, a function of predictor and criterion, and that this limitation poses an ongoing challenge for all psychological assessment instruments.
Meyer provides an additional broad overview chapter (Chapter 25) of psychometric evidence for performance-based (i.e., projective) personality tests, with a primary focus on the Rorschach and Thematic Apperception Test (TAT; Murray, 1943). To contend with potential interpretive biases, psychometric data are drawn exclusively from systematic metaanalytic reviews and presented along with the evidence for alternative measures in psychology, psychiatry, and medicine so readers can compare results across areas of applied health care. The results from 184 meta-analyses on interrater reliability, test-retest reliability, and validity reveal that the psychometric evidence for the Rorschach and TAT is similar to the evidence for alternative personality tests, for tests of cognitive ability, and for a range of medical assessment procedures. As such, the evidence suggests that the Rorschach and TAT should continue to be used as sources of information that are integrated with other findings in a sophisticated and differentiated psychological assessment.
The analyses presented by Meyer address several issues in a very detailed manner and one could reasonably wonder whether such extensive analyses are necessary. However, despite prior meta-analyses (Atkinson, Quarrington, Alp, & Cyr, 1986; Bornstein, 1996, 1999; Hiller et al., 1999; Meyer, 2000; Meyer & Archer, 2001; Meyer & Handler, 1997; Meyer et al., 2001; Parker, Hanson, & Hunsley, 1988; Rosenthal et al., 2001), several critics have continued to claim that projective assessment reliability and validity remain poor or inadequate. Viglione and Hilsenroth (2001) have pointed out important problems and inconsistencies in the arguments of those critical of projective techniques and have reviewed evidence at
the individual study level indicating reliability and validity issues are sound. The detailed findings reported by Meyer should serve to further solidify this evidentiary foundation.
SPECIFIC INSTRUMENTS
Each of the next seven chapters describes a specific test and reviews current psychometric data, research findings, and the clinical utility of the measure. Weiner (Chapter 26) discusses the current status of the Rorschach. His chapter reviews the conceptual basis of the measure and summarizes current research findings, psychometric characteristics, and clinical practice trends. Weiner also discusses the utility of Rorschach applications, the admissibility of Rorschach testimony into evidence in legal cases, cross-cultural considerations in Rorschach assessment, and the computerization of Rorschach results, as well as the current and future status of the instrument. Cumulative research findings presented by Weiner document that the Rorschach can be reliably scored; that it shows good test-retest reliability; and that the effect sizes found in correlating the Rorschach with external criteria are equivalent to those found for the MMPI or MMPI-2 and demonstrate as much validity as can be expected for personality tests. Because Rorschach assessment facilitates decision making that is based on personality characteristics, the Rorschach is frequently found useful in the practice of clinical, forensic, and organizational psychology, particularly with respect to such matters as treatment planning. Survey data and research presented indicate that the Rorschach is widely accepted in the courtroom and is culturally fair in its applicability to diverse national and ethnic groups. Software programs are available to assist in the scoring and interpretation of Rorschach protocols. Although reservations have been expressed in some quarters about the validity and utility of Rorschach assessment, available evidence indicates that there is sustained interest among knowledgeable assessment psychologists in using the Rorschach and conducting research with it.
The Moretti and Rossini chapter (Chapter 27) reviews the origins and development of the Thematic Apperception Test. It has been used continuously as a lifespan projective technique in clinical assessment and personality research for nearly 65 years. The TAT, similar to the Rorschach, has retained its popularity despite the psychometric challenges of critics (Lilienfeld, Wood, & Garb, 2000). The authors provide evidence that the TAT can indeed be used in psychometrically satisfactory ways. The authors also recognize potential limitations in that some TAT research is limited to single or small sets of variables, as seen in the more recent development of
clinically relevant and empirically adequate coding systems that are intentionally very limited in scope. Such coding systems build upon the rich tradition of the measurement of individual or social motivation and their correlates. A distinctive aspect of this chapter is that it suggests a more applied use of the TAT as a semistructured technique in clinical settings. The role of clinical personality assessment using the TAT is better understood as generating an understanding of the patient’s inner world, situational issues, and dynamics that will hopefully advance the therapeutic process. These authors also recommend using the TAT directly within the psychotherapeutic setting to explore the experience-near nature of the instrument. In addition, the use of empirical and clinically relevant coding systems (e.g., Social Cognition and Object Relations Scale [SCORS]; Westen, 1995) are reviewed. Issues regarding cross-cultural investigations, card selection, narrative recording, and appropriate reeducation concerning the theoretical aspects of the technique (e.g., Rossini & Moretti, 1997) are discussed.
Sentence completion tests (SCTs) are commonly used techniques in adult personality assessment. The chapter by Sherry, Dahlen, and Holaday (Chapter 28) highlights the variety of SCTs that have been developed over the years and provides substantial information about the Rotter Incomplete Sentences Blank (RISB; Rotter, Lah, & Rafferty, 1992), the most widely used SCT. Following an overview of the history of SCTs, the RISB is described in terms of its theoretical rationale, its development, and its psychometric properties. Discussion then broadens to the range of applicability and limitations of SCTs in general, addressing their use with diverse populations and persons with disabilities. The chapter also discusses the use of SCTs with computers, research, and the future of SCTs. This particular review is distinctive in that SCTs are reviewed in general and a comprehensive table of over 40 SCTs found in the literature is provided including the name of each test, the purpose or theory of the SCT, and the original citation for each test. The authors recommend that SCTs be utilized more fully in clinical settings as meaning-making exercises for both the assessment and facilitation of the therapeutic process.
The primary focus of the Handler, Campbell, and Martin chapter (Chapter 29) is the review and integration of research as well as clinical methodology for the Draw-A-Person Test (DAP; Machover, 1949), the House-Tree-Person Test (H-T-P; Buck 1948), and the Kinetic Family Drawing Test (K-F-D; Burns & Kaufman, 1970). The chapter includes a brief introduction and description of each test, including administration instructions. The particular advantages and disadvantages of each test are also discussed. Special attention is given to the effects of culture on each of the three instruments. Information is also supplied to assist the reader in critically evaluating each test in terms of its applicability, as well as information concerning its limitations in clinical application. One unique contribution of the chapter is that it relates early research and conceptualization concerning graphic assessment techniques to more recent findings. A second unique contribution concerns the evaluation of much past validation research design as oversimplified and as inappropriate, necessarily leading to negative findings. Instead, the recommended validity research approach is a design that is most similar to the way(s) in which graphic techniques are used in clinical assessment. The chapter discusses validity research findings from the use of an experiential paradigm in which a clinically focused phenomenological approach has resulted in significant positive results for graphic techniques. The chapter also discusses the detection of emotional problems through the use of an integrated constellation of variables and describes several welldesigned validity studies, as well as the need for detailed normative data on gender and cultural subgroups.
The history, theoretical basis, and development of the Hand Test (Wagner, 1983) are reviewed by Sivec, Waehler, and Panek (Chapter 30). The scoring system of this measure is presented and the psychometric properties (i.e., interscorer agreement, norms, reliability, and validity) of the test are evaluated, based upon current psychometric standards. Summaries of Hand Test research are provided for individuals diagnosed with mental retardation and for older adults. In contrast to previous reviews that organize Hand Test data according to clinical or diagnostic groups studied, the current review represents a comprehensive effort to organize and evaluate research data according to scoring category. This approach allows the reader to review relevant data for specific scores. In addition, this chapter provides the first comprehensive review of the Hand Test literature since the revised manual was published in 1983. Recommendations for use of the Hand Test in clinical and organizational settings are provided. In this regard, the Hand Test has consistently shown its utility as a measure of psychopathology and actingout behavior. In addition, certain Hand Test variables have been associated with specific clinical disorders. The extensive use of the Hand Test in several diverse cultures leads to the suggestion for an international Hand Test manual. Updated norms and further investigation of the Hand Test with specific diagnostic groups is also recommended.
The chapter by Fowler (Chapter 31) reviews the historical, theoretical, and empirical foundations of applying thematic and content analysis to patient narratives of their earliest childhood memories in order to obtain information regarding a wide array of clinically relevant issues (i.e., personality types, degree of psychological distress, aggressiveness, substance abuse, object relations, and affect). In addition, the assessment of adolescent and child psychopathology as well as the use of early memories to evaluate treatment outcomes are reviewed. Based upon available empirical evidence, it appears that early childhood memories can be a useful and reliable tool for assessing some aspects of psychological functioning. This would include the estimation of personality types, the assessment of potential aggressiveness and substance abuse as well as the quality of object representations and affect tone. Empirical studies demonstrate that clinical judgments and scoring systems for early memories can substantially improve our understanding of defensive denial and its impact on physiological functioning. This finding further demonstrates that projective techniques can be utilized to supplement selfreport measures of distress and psychological disturbance. Although limited, data from outcome studies seem promising for the use of early memories as a measure of internal change, but the lack of norms and test-retest reliability data currently limit these findings. In addition, Fowler addresses potential areas of concern such as the preference of investigators creating new scales to assess an ever-expanding array of psychological functions, rather than developing a program of systematic research to replicate and build on previous studies. However, in recent years several scoring systems have been proposed to integrate and standardize administration and scoring. The author concludes by noting that further work is required in order to validate specific scoring systems, especially studies that replicate initial findings utilizing existing systems.
The last chapter in this section on specific measures presents a new test that examines the intersection of attachment theory and projective assessment through the lens of the Adult Attachment Projective (AAP; George, West, & Pettem, 1999). The AAP is a new assessment technique that emphasizes the role of defensive processes in the organization of individual differences in attachment status. The chapter by George and West (Chapter 32) begins with a discussion of the attachment concept of defense as conceptualized by Bowlby’s attachment theory (1980). The chapter then describes the AAP, providing an overview of the coding system and validation data for this new measure. The authors then return to the topic of defenses, using AAP story examples to highlight how Bowlby’s conceptualization of defensive exclusion differentiates secure, dismissing, preoccupied, and unresolved attachment status in adults. With the projective assessment of adult attachment as the frame of reference, the chapter describes the intricacies of defensive operations, the analysis of projective story content, and discourse that differentiates among representational patterns of attachment. The chapter concludes with a discussion of how projective methodology is consonant with attachment theory and, as demonstrated through the AAP, contributes to new insights regarding attachment theory and research. The chapter makes a unique contribution to the literature in that it presents a new tool that to date has been demonstrated to be a valid assessment of individual differences in adult attachment representation. Furthermore, these authors provide a new perspective regarding the role of defensive exclusion as it functions in adult attachment representations as well as clinical examples of attachment representations.
SPECIFIC CONTENT AREAS
Projective techniques allow clinicians to study samples of behavior collected under similar conditions in different native languages around the world (e.g., Bellak & Abrams, 1997; Erdberg & Schaffer, 1999, 2001). There is an efficiency to sampling behaviors with such techniques to develop one’s understanding and appreciation of developmental changes across the age span and across all types of disorders and problems. In addition, the variety of scoring systems for different measures addresses a wide range of clinical, personality, forensic, developmental, cognitive, and neuropsychological constructs. For example, the Rorschach allows one to develop a common, experientially based database for the problem-solving practices and internal representations of clients from age 5 through old age. One could identify many other single purpose scales within a specific content or construct area that might compete well with the Rorschach, but to produce the same benefits one would have to master and monitor developments in perhaps 100 alternative instruments. To make cost-benefit comparisons ecologically valid, one would have to envision a full range of cost and benefit equivalents, such as the expense of purchasing kits, test blanks, computer programs, and paying per use fees. Also, all projective techniques provide an efficient way to collect a behavior sample outside of interview behavior. Psychologists’ time is valuable, but so is the client’s time, so that is another cost to be entered into cost-benefit analysis. Mastering one test that assesses an array of clinically relevant functions is efficient because it eliminates the need for many contentspecific tests. As a result, we can pick and choose more judiciously and master select instruments within an assessment battery, rather than misuse a large number of tests for all the potential purposes that a few broadband measures of personality address. As such, the next seven chapters are organized around the use of projective techniques in the assessment of several specific constructs pertinent in applied clinical work.
Of particular interest to psychodynamically oriented clinicians will be the chapter by Stricker and Gooen-Piels (Chapter 33) that updates a previous comprehensive review on the empirical study of projective assessment of object relations used with adults conducted by Stricker and Healey (1990) more than a decade ago. The authors begin with a discussion of the theory of object relations and describe ways in which this construct may be operationalized. They then present reliability and validity data for several projective measures of object relations. This body of empirical research supports both the construct of object relations and the accuracy of projective techniques to measure this construct. However, these authors also discuss problems that arise in attempting to assess constructs that are unconscious and make suggestions for future programmatic research designed to increase the ability to assess a range of object relations.
The chapter by Porcerelli and Hibbard (Chapter 34) provides a review of the three most prominent defense mechanism assessment scales for projective test data: the Lerner Defense Scale (Lerner, 1991), the Rorschach Defense Scale (Cooper, Perry, & Arnow, 1988), and the Defense Mechanisms Manual (Cramer, 1991). These scales have received empirical validation and can be easily utilized as part of a comprehensive psychological test battery. The chapter includes sections on the theory of defense mechanisms, a discussion of the relationship between defenses and psychopathology, and a comprehensive review of each scale. Reviews include a detailed description of each scale, the most up-to-date reliability and validity information, and a balanced discussion of strengths and limitations. This review demonstrates the increasing empirical support for the validity of defense mechanisms and emphasizes their importance in developing a dynamic understanding of personality strengths, adaptation, and psychopathology. The authors provide compelling evidence that the assessment of defense mechanisms is an indispensable part of any comprehensive personality test battery and include suggestions for the clinical use of these defense scales.
Building on a substantial body of previous research concerning interpersonal dependency (Bornstein, 1993, 1996, 1999), the chapter by Bornstein (Chapter 35) reviews the projective assessment of this construct. This review delineates the strengths and limitations of projective test variables assessing dependency as well as explores useful research and clinical applications. The chapter presents a broad definition of interpersonal dependency and the implications of the evolution of this construct for psychologists’ understanding of dependent personality traits. Projective instruments for assessing interpersonal dependency are evaluated, both individually and collectively. These projective instruments are then contrasted with self-report dependency measures. Strengths and limitations of both assessment methods are described. Finally, a conceptual framework for integrating projective and self-report test data is outlined, and future directions for research in projective dependency testing are discussed.
While no definitive borderline profile exists, projective assessment data from numerous instruments has proven to be useful in describing, diagnosing, and formulating treatment plans for patients with borderline psychopathology. The chapter by Blais and Bistis (Chapter 36) reviews the development of the borderline personality concept, from both the DSM and psychodynamic perspectives. The authors provide an updated review of the literature that is unique in that it organizes findings by the specific assessment instrument. The ability of projective assessment data to identify and describe patients with borderline psychopathology is delineated and focuses in particular upon the Rorschach, the TAT, and the Early Memories Test. The review of the literature suggests that borderline psychopathology can consistently be identified in projective assessment by (1) the systematic evaluation of thought quality (i.e., inner-outer boundary disturbance), (2) internalized object representations (i.e., malevolent), (3) degree and quality of aggression (intense, unmodulated, and destructive), and (4) level of defensive functioning (i.e., splitting). In addition, these authors discuss how a comprehensive assessment of projective data can help to establish the severity of a patient’s condition and can yield meaningful recommendations regarding treatment options.
Many individuals who seek treatment have experienced an emotionally, physically, and/or sexually traumatic event(s). The chapter by Armstrong and Kaser-Boyd (Chapter 37) reviews how projective tests may contribute to the understanding of trauma reactions and clinical issues related to trauma syndromes. This review begins with an overview of different theoretical and clinical perspectives on the nature of trauma. The chapter also provides a review of research findings for several variables of the Rorschach and TAT figural in the assessment of trauma and dissociation. While this chapter focuses more on the assessment of trauma reactions in civilian rather than military populations, it provides a complementary discussion to a recent review focusing on the projective assessment of stress syndromes in military personnel (Sloan, Arsenault, & Hilsenroth, 2001). Finally, a conceptual framework for integrating projective test data in relation to the assessment of trauma and dissociation is detailed and future directions for research in the projective assessment of traumatic sequelae are discussed.
The use of projective techniques in suicide risk assessment has a long and rich history. The chapter by Holdwick and Brzuskiewicz (Chapter 38) reviews the role that projective techniques can play in evaluating suicidal ideation and patient risk for self-harm, both as a proximal indicator of risk and in terms of distal risk prediction. While past reviews have focused on a limited number of projective methods (Rorschach, TAT), this chapter includes these prominent projective methods and less frequently used or researched techniques. Also unique to this review is the specific focus on the use of projective techniques for specific age groups (child, adolescent, adult). Empirical evidence for the use of projective techniques, specifically the Rorschach, in suicide risk assessment support their continued use in assisting clinicians who work with potentially suicidal patients. The Rorschach Comprehensive System’s Suicide Constellation (S-CON; Exner, 1993) remains the only, projective or self-report, scale that has been replicated as a predictive measure of future suicide or severe suicide attempt within 60 days of initial testing in a clinical sample (Exner & Wiley, 1977; Fowler, Piers, Hilsenroth, Holdwick, & Padawer, 2001). Also, this chapter presents information on newer scoring methods for the TAT with adults and Human Figure Drawings with children. Focus is also given to recently developed variables derived from projective techniques that may provide additional means for examining suicidal ideation and risk with patients. Issues regarding reliability, validity (concurrent, predictive, discriminant), and clinical utility for suicide assessment are discussed, as are limitations of these instruments.
Projective techniques not only provide an excellent means of assessing ideation or fantasies but they can also be useful in identifying formal disturbances in perception and thought organization. While several recent authors have provided empirical reviews of the validity of projective techniques in the assessment of thought disorder (Bellak & Abrams, 1997; Hilsenroth, Fowler, & Padawer, 1998; Jørgensen, Andersen, & Dam, 2000; W. Perry & Braff, 1998; W. Perry, Geyer, & Braff, 1999; Viglione, 1999; Viglione & Hilsenroth, 2001), the chapter by Kleiger (Chapter 39) seeks to organize conceptual and theoretical approaches to understanding the nature of thought disorder. Integrating contributions from the psychiatric, psychoanalytic, and psychological literature on thought disorder, Kleiger constructs a group of conceptual categories that can be accommodated to a range of projective instruments. The chapter offers a unique approach to thinking about the conceptual underpinnings of forms of disordered thought that can be used with a range of projective instruments for identifying thought disorder. The chapter concludes with a discussion of promising new avenues for empirical studies to develop formal scoring systems designed to capture various manifestations of disordered thinking using a variety of projective techniques.
SPECIAL POPULATIONS AND SETTINGS
Minassian and Perry (Chapter 40) review the use of projective personality instruments in the assessment of neurologically impaired individuals. These authors examine two distinct approaches to this topic. First, they discuss the traditional role of projective assessment in populations with neurological deficits, where the major effort is to understand personality organization. Specific populations such as head-injured patients, patients with cerebral dysfunctions, aging patients, dementia patients, and neurologically impaired children and adolescents are reviewed. These authors caution that some “personality” based interpretations of projective test performance may overlook the significance of underlying cognitive deficits and their impact on projective test behavior (Zilmer & Perry, 1996). Thus a “brain-behavior” approach to the examination of projective test data is warranted, where a primary focus of assessment is on the individual’s neuropsychological capabilities. In the second section of the chapter, Minassian and Perry propose that projective measures, such as the Rorschach Inkblot test, can be conceptualized from a cognitive perspective as complex problem-solving tasks. This section includes a review of the history of the Rorschach as a neuropsychological instrument and contributions of the Comprehensive System (CS) to the conceptualization of the Rorschach as a cognitive problem-solving task. The authors also include illustrations of how each phase of the Rorschach response process involves complex brain functions mediated by specific neural circuitry, the potential weaknesses of the CS in the arena of neuropsychological assessment, and the introduction of a “process” approach to examining neuropsychological deficits with projective instruments (W. Perry, Potterat, Auslander, Kaplan, & Jeste, 1996). Minassian and Perry conclude with suggestions regarding further integration of neuroscience, such as neuro-imaging, paired with performance on projective techniques, to further illustrate the important role that “personality” tests play in the assessment of neuropsychological functioning.
Although few studies have been conducted on the issue of malingering detection using projective personality tests since G. Perry and Kinder (1990) and Schretlen (1997) published their literature reviews, the aim of the chapter by Elhai, Kinder, and Frueh (Chapter 41) is to comprehensively discuss both the relevant literature and methodological issues of this topic. An introduction to the projective assessment of malingering is presented, followed by a review of the Rorschach’s ability to detect malingering, a review of additional projective tests used to assess malingering (including the TAT, Group Personality Projective Test [GPPT; Cassel & Brauchle, 1959] and SCT), a summary of findings, a discussion of methodological issues, and implications for clinical practice. Controlled studies have demonstrated the effectiveness of several indices to detect significant differences between simulator and comparison groups. In addition, the Rorschach has demonstrated an ability to produce valid protocols from subjects attempting to conceal psychological disturbance (i.e., emotional distress, self-critical ideation, and difficulties in interpersonal relationships) on self-report measures of personality (Ganellen, 1994). However, the studies utilizing projective tests in malingering assessment are not easily comparable, as they have examined a wide array of variables. Since no cutoff scores are available for projective tests in discriminating malingered from genuine protocols, these authors discuss salient limitations of using decision rules for the identification of malingering in clinician practice.
In addition to the recent general criticism of projective techniques, three recent journal articles have expressed specific concerns regarding the admissibility and use of data obtained from projective techniques in courtroom testimony (Garb, 1999; Grove & Barden, 1999; Wood, Nezworski, Stejskal, & McKinzey, 2001). Like the general attacks on projective techniques, these specific criticisms regarding forensic use have also been countered by several conceptual and empirical rebuttals (Gacono, 2002, in press; Gacono, Evans, & Viglione, in press; Jumes, Oropeza, Gray, & Gacono, 2002; Ritzler, Erard, & Pettigrew, 2002a, 2002b; Viglione & Hilsenroth, 2001). The chapter by McCann (Chapter 42) extends and updates (see McCann, 1998) this issue as well as provides further information for clinicians utilizing projective assessment methods in forensic settings. Several relevant issues are presented, including the legal standards for admissibility and professional standards for using psychological tests in legal settings. Evidentiary standards such as the Frye test (United States v. Frye, 1923), Daubert standard (1993), and new developments in Federal Rules of Evidence 702 (O’Conner & Krauss, 2001) are discussed, as well as professional standards that have been offered to guide the selection of assessment methods in forensic cases. Recognition is given to the fact that the use of projective methods has been controversial. The author reports that research on the patterns of psychological test use and a review of case law indicate that data gathered from projective methods are virtually always admitted into testimony. Also, projective methods appear to be widely used in forensic settings and courts have generally scrutinized the testimony of experts, rather than the individual methods employed. However, when expert testimony based on projective test data is ruled inadmissible, this decision is almost always based on the application or relevance of that testimony to the legal issue in question and not on the specific assessment instruments utilized by that expert. McCann concludes by offering some guidelines to assist practitioners in deciding whether to use projective methods in forensic settings, including the need to consider empirical support for the method and the amount and type of information such methods provide.
The chapter by Ritzler (Chapter 43) offers the first general review of empirical studies on the cultural relevance of projective personality assessment methods; specifically, he includes the Rorschach, apperception tests, and figure drawings. The first issue considered by Ritzler is possible differences in data due to the race of the individual. He reports no conclusive evidence of racial differences for any of the methods in this chapter. However, existing data are limited and primarily come from comparisons of samples of African Americans and Caucasian Americans from middle and upper socioeconomic levels. No studies have attempted to select participants from culturally distinct racial communities. A significant focus of this chapter is the “culture-free” and “culture-sensitive” aspects of the assessment methods. Culture-free methods are necessary to assess personality characteristics shared by all humans regardless of culture. Culture-sensitive methods are necessary to assess the influence of different cultures on personality functioning.
The author’s review of the Rorschach literature suggests that this measure essentially yields similar results across many different cultures. The few culture-sensitive findings for the Rorschach mostly come from early studies that compared modern cultures with primitive cultures. This conclusion is supported by current research that demonstrates very limited differences between nonpatient African American and Caucasian American adults matched on important demographic variables (Presley, Smith, Hilsenroth, & Exner, 2001). Finally, Meyer (2002) extends these findings by conducting a series of analyses to explore potential ethnic bias in Rorschach CS variables with a patient sample. After matching on several salient demographic variables, ethnicity revealed no significant findings and principal component analyses revealed no evidence of ethnic bias in the Rorschach’s internal structure. These findings are equivalent (Kline & Lachar, 1992; McNulty, Graham, Ben-Porath, & Stein, 1997; Neisser et al., 1996; Timbrook & Graham, 1994) or superior (Arbisi, Ben-Porath, & McNulty, 2002) to racial bias found within selfreport personality and cognitive assessment literature.
In contrast to the Rorschach, apperception tests yield results that suggest these methods are more culture sensitive than culture free. This is particularly true when the stimulus pictures are adjusted to include culture-specific features (Bellak & Abrams, 1997). Compared to the other methods, fewer studies have been conducted of the cultural relevance of figure drawings. However, the results that do exist are more equivocal for figure drawings than for the Rorschach or apperception tests. The limited data suggest that drawings may represent some middle ground between culture-free and culture-sensitive assessment.
Fischer, Georgievska, and Melczak (Chapter 44) present a useful approach to providing assessment feedback based on information derived from projective techniques. In collaborative assessment, the goal is to understand particular life events in everyday terms using assessment data as points of access to the client’s world. This collaborative approach to psychological assessment includes a broadened focus of attention beyond the scope of basic information gathering (Fischer, 1985/1994). In this therapeutic assessment model (Finn & Tonsager, 1997), the “assessors are committed to (a) developing and maintaining empathic connections with clients, (b) working collaboratively with clients to define individualized assessment goals, and (c) sharing and exploring assessment results with clients” (p. 378). Establishing a secure working alliance in the assessment phase of treatment may help address the despair, poor interpersonal relationships, feelings of aloneness, and experience of distress that frequently motivate patients to seek psychotherapy. In addition, by expanding the focus of assessment, both patient and clinician gain knowledge about treatment issues, which, in turn, provides the opportunity for a more genuine interaction during the assessment phase as well as in formal psychotherapy sessions. Early empirical findings examining this approach to psychological assessment have found that use of this model may decrease the number of patients who terminate treatment prematurely and may impact the patient’s experience of assessment feedback sessions (Ackerman, Hilsenroth, Baity, & Blagys, 2000). Additional advantages include decreases in symptomatic distress and increases in self-esteem and facilitation of the therapeutic alliance (Ackerman et al., 2000; Finn & Tonsager, 1992; Newman & Greenway, 1997). The improvement of the therapeutic alliance developed during the assessment was also later related to alliance early in psychotherapy (Ackerman et al., 2000).
This chapter provides an overview of collaborative practices, such as the exploration of both problematic and adaptive behavior. In addition, the authors describe how to discuss various actions, interactions, issues, and patterns of relating during the assessment process. Suggestions are made on how to individualize feedback to the client in terms of recognizing unsuccessful patterns and potentially adaptive alternatives. During this process, the assessor revises impressions and accesses real-life examples. Extensive excerpts from assessment sessions illustrate these practices with a variety of projective techniques. How projective techniques work and how they lend themselves to collaborative practices are also discussed. The concluding section points out the confluence of collaborative practices within several theories of clinical practice.
APPLICATIONS FOR CHILDREN AND ADOLESCENTS
A number of previous chapters in this volume have included information on the use and implications of various instruments, scales, and content areas with children and adolescents. In addition, this section contains three chapters that specifically address applications for the use of projective techniques with children and adolescents. In the first of these chapters, Westenberg, Hauser, and Cohn (Chapter 45) provide a review regarding the projective assessment of psychological development and social maturity with SCTs. A sentence completion test for measuring maturity in adults, the Washington University Sentence Completion Test (WUSCT; Loevinger, 1985), was developed by Loevinger and her colleagues to assess the relevance of these constructs for clinical practice, organizational settings, and research protocols. Westenberg and his colleagues have recently developed a version of the WUSCT for use with children and youth (ages 8 and older), the Sentence Completion Test for Children and Youths (SCT-Y; Westenberg, Treffers, & Drewes, 1998). Both instruments are discussed in relation to Loevinger’s theory of personality development, which portrays personality growth as a series of developmental advances in impulse control, interpersonal relations, and conscious preoccupations. This chapter provides a comprehensive review of the WUSCT and recently developed SCT-Y. The authors provide an overview of the theoretical and empirical basis of the WUSCT and SCT-Y as measures of psychological and social maturity. The authors report research on these measures indicating excellent reliability, construct validity, and clinical utility. The chapter concludes with a discussion of the practical uses of these measures in clinical and organizational settings as well as recommendations for future research.
The chapter by Kelly (Chapter 46) outlines and evaluates prominent Rorschach and TAT content scales used to assess object representation measures in children and adolescents. The Urist (1977) Mutuality of Autonomy Scale (MOAS) and the Social Cognition and Object Relations Scale (SCORS) developed by Westen and colleagues (Westen, 1995; Westen, Lohr, Silk, Kerber, & Goodrich, 1989) are the primary scales of focus in this chapter. Also, the use of an early memory task, that is, the Comprehensive Early Memories Scoring System (CEMSS) developed by Bruhn (1981), in relation to use with children and adolescents is reviewed. Studies presenting reliability and validity measures for the MOAS, SCORS, and CEMSS are presented. This chapter by Kelly represents the first effort to comprehensively integrate the child and adolescent literature relating to object representation assessment utilizing projective techniques. Findings indicate impressive reliability and validity information pertaining to an evaluation of a child’s or an adolescent’s object representations.
The primary focus of the chapter by Russ (Chapter 47) is the measurement of the expression of affect in children’s pretend play. There is a specific focus on the Affect in Play Scale (APS; Russ, 1993). The APS was developed to meet the need for a reliable and valid scale that measures affective expression in pretend play for 6- to 10-year-old children. The chapter covers important areas such as: test description and development, psychometric characteristics, range of applicability and limitations, cross-cultural factors, accommodation for populations with disabilities, legal and ethical considerations, computerization, current research studies, use in clinical practice, and future directions. This review is distinctive in that the APS is placed in a projective assessment framework, recent research with the APS is included, and a wide range of clinically relevant issues concerning the use of the APS are considered. The main finding of the chapter is that the affective and cognitive processes measured by the APS are predictive of theoretically relevant criteria of creativity, coping, and adjustment. Both cognitive and affective processes are stable over a 5-year period. A summary of the extant research suggests that the APS measures processes that are important in child development, that they predict adaptive functioning in children, and that they are separate from what intelligence tests measure.
CONCLUSION AND FUTURE PERSPECTIVES
In addressing several different tests as well as specific content areas, populations, and issues, the chapters in this volume provide readers with an informed appreciation for the substantial but often overlooked research basis for the reliability, validity, and clinical utility of projective techniques. Interrater reliability of projective techniques has been found to be good (ICC/j !.60) to excellent (! .75) based on accepted psychometric standards (Fleiss, 1981; Fleiss & Cohen, 1973; Garb, 1998; Shrout & Fleiss, 1979). Test-retest reliability data for projective techniques have been shown to be at least equivalent or superior to other psychological tests. Likewise these measures have demonstrated validity both broadly and in specific domains. Extensive normative data are available for several different scoring systems across a number of these techniques and the current collection of updated normative samples is under way for several measures. Also, projective techniques have been shown to provide reliable, valid, and clinically useful information across a range of ethnic diversity and internationally. Thus, several projective techniques, by virtue of the accumulated research, are now better prepared to stand the scrutiny of current psychometric standards. This is even more apparent when the same standards are applied equally to self-report, interview, neurological, and intelligence tests. The data from each of these assessment methods are used to provide a context in which to evaluate the efficacy of projective techniques.
In addition to providing a thorough, relevant review of the essential empirical literature, all of the contributions to this volume discuss the clinical utility of various measures in the context of a responsible psychological assessment process. This information derived from projective techniques can be utilized to address a broad range of relevant issues in psychological assessment. The chapters in this volume explore the interpretation and application of projective techniques in a complex, sophisticated, and integrated manner. Many of the authors describe such a configural, synthetic approach to projective test interpretation that is fundamental to the clinical/ actuarial method. In this method projective techniques provide an ecologically valid and informed understanding of interactive probabilities to increase accuracy of in vivo decision making in applied psychology.
In conclusion, it would seem prudent to encourage clinicians and researchers alike to employ multiple methods of psychological assessment, including projective techniques, and to utilize this information in a systematic and theoretically consistent fashion. Understanding the variety of options available for the measurement of personality and psychopathology is useful in order to compare and select among the various methods. In stark contrast to the opinions offered by Lilienfeld et al. (2000), the chapters in this volume support and extend previous research and applied clinical work utilizing projective techniques in psychological assessment. These contributions provide converging lines of evidence and support the use of projective techniques as a valuable method in the assessment of personality and psychopathology as well as contribute to a conceptual understanding of pertinent treatment issues. It is also important that psychologists continue to examine the manner in which projective techniques aid in understanding the idiographic richness and complexity of an individual. The results of such inquiry, utilizing both structural and theoretically derived variables, will undoubtedly provide important and meaningful information to facilitate psychological assessment and treatment.
REFERENCES
Ackerman, S., Hilsenroth, M., Baity, M., & Blagys, M. (2000). Interaction of therapeutic process and alliance during psychological assessment. Journal of Personality Assessment, 75, 82–109.
- American Psychiatric Association. (1994). Diagnostic and statistical manual of mental disorders (4th ed.). Washington, DC: Author.
- Arbisi, P., Ben-Porath, Y., & McNulty, J. (2002). A comparison of MMPI-2 validity in African American and Caucasian psychiatric inpatients. Psychological Assessment, 14, 3–15.
- Atkinson, L., Quarrington, B., Alp, I.E., & Cyr, J.J. (1986). Rorschach validity: An empirical approach to the literature. Journal of Clinical Psychology, 42, 360–362.
- Bellak, L., & Abrams, D. (1997). The TAT, the CAT, and the SAT in clinical use (6th ed.). Boston: Allyn & Bacon.
- Block, J. (1995). A contrarian view of the five-factor approach to personality description. Psychological Bulletin, 117, 187–215.
- Bornstein, R.F. (1993). The dependent personality. New York: Guilford Press.
- Bornstein, R.F. (1996). Construct validity of the Rorschach Oral Dependency scale: 1967–1995. Psychological Assessment, 8, 200–205.
- Bornstein, R.F. (1999). Criterion validity of objective and projective dependency tests: A meta-analytic assessment of behavioral prediction. Psychological Assessment, 11, 48–57.
- Bornstein, R.F. (2002). A process-dissociation approach to objectiveprojective test score interrelationships. Journal of Personality Assessment, 78, 47–68.
- Bowlby, J. (1980). Attachment and loss: Volume 3. Loss. New York: Basic Books.
- Bruhn, A. (1981). Children’s earliest memories: Their use in clinical practice. Journal of Personality Assessment, 45, 258–262.
- Buck, J. (1948). The H-T-P. Journal of Clinical Psychology, 4, 151–159.
- Burns, R., & Kaufman, S. (1970). Kinetic Family Drawings (K-F-D): An introduction to understanding children through kinetic drawings. New York: Brunner/Mazel.
- Butcher, J.N., Dahlstrom, W.G., Graham, J.R., Tellegen, A.M., & Kaemmer, B. (1989). MMPI-2: Manual for administration and scoring. Minneapolis: University of Minnesota Press.
- Camara, W., Nathan, J., & Puente, A. (2000). Psychological test usage: Implications in professional use. Professional Psychology: Research and Practice, 31, 141–154.
- Campbell, D., & Fiske, D. (1959). Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin, 56, 81–105.
- Cassel, R., & Brauchle, R. (1959). An assessment of the fakability of scores on the Group Personality Projective Test. Journal of Genetic Psychology, 95, 239–244.
- Clemence, A., & Handler, L. (2001). Psychological assessment on internship: A survey of training directors and their expectations for students. Journal of Personality Assessment, 76, 18–47.
- Colvin, R., Block, J., & Funder, D. (1995). Overly positive self evaluations and personality: Negative implications for mental health. Journal of Personality and Social Psychology, 68, 1152– 1162.
- Cooper, S., Perry, J., & Arnow, D. (1988). An empirical approach to the study of defense mechanisms: 1. Reliability and preliminary validity of the Rorschach Defense Scales. Journal of Personality Assessment, 52, 187–203.
- Cramer, P. (1991). The development of defense mechanisms: Theory, research, and assessment. New York: Springer-Verlag.
- Daubert v. Merrell Dow Pharmaceuticals, Inc., 509 U.S. 579, 113 S.Ct. 2786, (1993).
- Dawes, R.M. (1994). House of cards: Psychology and psychotherapy built on myth. New York: Free Press.
- Dozier, M., & Kobak, R. (1992). Psychophysiology in attachment interviews: Converging evidence for deactivating strategies. Child Development, 63, 1473–1480.
- Eisman, E., Dies, R., Finn, S.E., Eyde, L., Kay, G.G., Kubiszyn, T., et al. (2000). Problems and limitations in the use of psychological assessment in contemporary healthcare delivery. Professional Psychology: Research and Practice, 31, 131–140.
- Erdberg, P., & Shaffer, T.W. (1999, July). International symposium on Rorschach nonpatient data: Findings from around the world. Symposium presented at the XVIth Congress of the International Rorschach Society, Amsterdam, The Netherlands.
- Erdberg, P., & Shaffer, T.W. (2001, March). An international symposium on Rorschach nonpatient data: Worldwide findings. Symposium presented at the annual convention of the Society for Personality Assessment, Philadelphia, PA.
- Exner, J.E. (1989). Searching for projection in the Rorschach. Journal of Personality Assessment, 53, 520–536.
- Exner, J.E. (1991). The Rorschach: A comprehensive system: Volume 2. Interpretation (2nd ed.). New York: Wiley.
- Exner, J.E. (1993). The Rorschach: A comprehensive system: Volume 1. Basic foundations (3rd ed.). New York: Wiley.
- Exner, J.E. (1996). Critical bits and the Rorschach response process. Journal of Personality Assessment, 67, 464–477.
- Exner, J.E., & Wiley, J. (1977). Some Rorschach data concerning suicide. Journal of Personality Assessment, 41, 339–348.
- Eysenck, H. (1959). The Rorschach Inkblot test. In O.K. Buros (Ed.), The fifth mental measurements yearbook (pp. 276–278). Highland Park, NJ: Gryphon Press.
- Finn, S.E., & Tonsager, M.E. (1992). Therapeutic effects of providing MMPI-2 test feedback to college students awaiting therapy. Psychological Assessment, 4, 278–287.
- Finn, S.E., & Tonsager, M.E. (1997). Information-gathering and therapeutic models of assessment: Complementary paradigms. Psychological Assessment, 9, 374–385.
- Fischer, C.T. (1985/1994). Individualized psychological assessment. Hillsdale, NJ: Erlbaum.
- Fleiss, J. (1981). Statistical methods for rates and proportions (2nd ed.). New York: Wiley.
- Fleiss, J., & Cohen, J. (1973). The equivalence of weighted kappa and the intraclass correlation coefficient as measures of reliability. Educational and Psychological Measurement, 33, 613–619.
- Fowler, C., Piers, C., Hilsenroth, M., Holdwick, D., & Padawer, R. (2001). Assessing risk factors for various degrees of suicidal activity: The Rorschach Suicide Constellation (S-CON). Journal of Personality Assessment, 76, 333–351.
- Frank, L.K. (1939). Projective methods for the study of personality. Journal of Psychology, 8, 389–413.
- Funder, D.C. (1997). The personality puzzle. New York: Norton.
- Gacono, C. (2002). Why there is a need for the personality assessment of offenders. International Journal of Offender Therapy and Comparative Criminology, 46, 271–273.
- Gacono, C. (in press). Introduction to a special series: Forensic psychodiagnostic testing. Journal of Forensic Psychology Practice.
- Gacono, C., Evans, B., & Viglione, D. (in press). The Rorschach in forensic practice. Journal of Forensic Psychology Practice.
- Ganellen, R. (1994). Attempting to conceal psychological disturbance: MMPI defensive response sets and the Rorschach. Journal of Personality Assessment, 63, 423–437.
- Garb, H.N. (1998). Studying the clinician: Judgment research and psychological assessment. Washington, DC: American Psychological Association.
- Garb, H.N. (1999). Call for a moratorium on the use of the Rorschach Inkblot test in clinical and forensic settings. Assessment, 6, 313–315.
- Garb, H.N., Florio, C.M., & Grove, W.M. (1998). The validity of the Rorschach and the Minnesota Multiphasic Personality Inventory: Results from meta-analyses. Psychological Science, 9, 402–404.
- Garb, H.N., Wood, J.M., Nezworski, M.T., Grove, W.M., & Stejskal, W.J. (2001). Towards a resolution of the Rorschach controversy. Psychological Assessment, 13, 433–448.
- George, C., West, M., & Pettem, O. (1999). The Adult Attachment Projective: Disorganization of adult attachment at the level of representation. In J. Solomon & C. George (Eds.), Attachment disorganization (pp. 462–507). New York: Guilford Press.
- Grove, W.M., & Barden, R.C. (1999). Protecting the integrity of the legal system: The admissibility of testimony from mental health experts under Daubert/Kumho analyses. Psychology, Public Policy, and the Law, 5, 224–242.
- Hiller, J.B., Rosenthal, R., Bornstein, R.F., Berry, D.T.R., & Brunell-Neuleib, S. (1999). A comparative meta-analysis of Rorschach and MMPI validity. Psychological Assessment, 11, 278–296.
- Hilsenroth, M.J., Fowler, C.J., & Padawer, J.R. (1998). The Rorschach Schizophrenia Index (SCZI): An examination of reliability, validity, and diagnostic efficiency. Journal of Personality Assessment, 70, 514–534.
- Hunsley, J., & Bailey, J.M. (1999). The clinical utility of the Rorschach: Unfulfilled promises and an uncertain future. Psychological Assessment, 11, 266–277.
- Hunsley, J., & Bailey, J.M. (2001). Wither the Rorschach? An analysis of the evidence. Psychological Assessment, 13, 472–485.
- Jackson, D. (1971). The dynamics of structured personality tests. Psychological Review, 78, 229–248.
- Jensen, A. (1965). The Rorschach Inkblot test. In O.K. Buros (Ed.), The sixth mental measurements yearbook (pp. 501–509). Highland Park, NJ: Gryphon Press.
- John, O., & Robins, R. (1994). Accuracy and bias in self-perception: Individual differences in self-enhancement and the role of narcissism. Journal of Personality and Social Psychology, 66, 206–219.
- Jørgensen, K., Andersen, T.J., & Dam, H. (2000). The diagnostic efficiency of the Rorschach Depression Index and the Schizophrenia Index: A review. Assessment, 7, 259–280.
- Jumes, M., Oropeza, P., Gray, B., & Gacono, C. (2002). Use of the Rorschach in forensic settings for treatment planning and monitoring. International Journal of Offender Therapy and Comparative Criminology, 46, 294–307.
- Kline, R.B., & Lachar, D. (1992). Evaluation of age, sex, and race bias in the Personality Inventory for Children (PIC). Psychological Assessment, 4, 333–339.
- Leary, T. (1957). Interpersonal diagnosis of personality. New York: Ronald.
- Lerner, P. (1991). Psychoanalytic theory and the Rorschach. Hillsdale, NJ: Analytic Press.
- Lerner, P. (1992). Toward an experiential psychoanalytic approach to the Rorschach. Bulletin of the Menninger Clinic, 56, 451–464.
- Lilienfeld, S.O., Wood, J.M., & Garb, H.N. (2000). The scientific status of projective techniques. Psychological Science in the Public Interest, 1, 27–66.
- Loevinger, J. (1985). Revision of the Sentence Completion Test for Ego Development. Applied Psychological Measurement, 3, 281–311.
- Machover, K. (1949). Personality projection in the drawing of the human figure. Springfield, IL: Charles Thomas.
- McCann, J.T. (1998). Defending the Rorschach in court: An analysis of admissibility using legal and professional standards. Journal of Personality Assessment, 70, 125–144.
- McClelland, D.C., Koestner, R., & Weinberger, J. (1989). How do self-attributed and implicit motives differ? Psychological Review, 96, 690–702.
- McNulty, J.L., Graham, J.R., Ben-Porath, Y., & Stein, L.A.R. (1997). Comparative validity of MMPI-2 scores of African American and Caucasian mental health center clients. Psychological Assessment, 9, 464–470.
- Meyer, G.J. (1997a). Assessing reliability: Critical correlations for a critical examination of the Rorschach Comprehensive System. Psychological Assessment, 9, 480–489.
- Meyer, G.J. (1997b). Thinking clearly about reliability: More critical correlations regarding the Rorschach Comprehensive System. Psychological Assessment, 9, 495–498.
- Meyer, G.J. (2000). On the science of Rorschach research. Journal of Personality Assessment, 75, 46–81.
- Meyer, G.J. (2001). Evidence to correct misperceptions about Rorschach norms. Clinical Psychology: Science and Practice, 8, 389–396.
- Meyer, G.J. (2002). Exploring possible ethnic differences and bias in the Rorschach Comprehensive System. Journal of Personality Assessment, 78, 104–129.
- Meyer, G.J., & Archer, R. (2001). The hard science of Rorschach research: What do we know and where do we go? Psychological Assessment, 13, 486–502.
- Meyer, G.J., Finn, S.E., Eyde, L., Kay, G.G., Moreland, K.L., Dies, R.R., et al. (2001). Psychological testing and psychological assessment: A review of evidence and issues. American Psychologist, 56, 128–165.
- Meyer, G.J., & Handler, L. (1997). The ability of the Rorschach to predict subsequent outcome: A meta-analysis of the Rorschach Prognostic Rating Scale. Journal of Personality Assessment, 69, 1–38.
- Meyer, G.J., Hilsenroth, M., Baxter, D., Exner, J., Fowler, C., Piers, C., et al. (2002). An examination of interrater reliability for scoring the Rorschach Comprehensive System in eight data sets. Journal of Personality Assessment, 78, 219–274.
- Murray, H.A. (1943). Thematic Apperception Test. Cambridge, MA: Harvard University Press.
- Neisser, U., Boodoo, G., Bouchard, T.J., Jr., Boykin, A.W., Brody, N., Ceci, S.J., et al. (1996). Intelligence: Knowns and unknowns. American Psychologist, 51, 77–101.
- Newman, M.L., & Greenway, P. (1997). Therapeutic effects of providing MMPI-2 test feedback to clients at a university counseling service: A collaborative approach. Psychological Assessment, 9, 122–131.
- O’Conner, M., & Krauss, D. (2001). Legal update: New developments in Rule 702. APLS News, 21, 1–4, 18.
- Ozer, D.J. (1999). Four principles for personality assessment. In L.A. Pervin & O.P. John (Eds.), Handbook of personality: Theory and research (2nd ed.; pp. 671–686). New York: Guilford Press.
- Parker, K.C.H., Hanson, R.K., & Hunsley, J. (1988). MMPI, Rorschach, and WAIS: A meta-analytic comparison of reliability, stability, and validity. Psychological Bulletin, 103, 367–373.
- Perry, G., & Kinder, W. (1990). Susceptibility of the Rorschach to malingering: A critical review. Journal of Personality Assessment, 54, 47–57.
- Perry, W. (2001). Incremental validity of the Ego Impairment Index: A re-examination of Dawes (1999). Psychological Assessment, 13, 403–407.
- Perry, W., & Braff, D. (1998). A multimethod approach to assessing perseverations in schizophrenia patients. Schizophrenia Research, 33, 69–77.
- Perry, W., Geyer, M.A., & Braff, D.L. (1999). Sensorimotor gating and thought disturbance measured in close temporal proximity in schizophrenic patients. Archives of General Psychiatry, 56, 277–281.
- Perry, W., Potterat, E.G., Auslander, L., Kaplan, E., & Jeste, D. (1996). A neuropsychological approach to the Rorschach in patients with dementia of the Alzheimer type. Assessment, 3, 351–363.
- Peterson, D. (1995). The reflective educator. American Psychologist, 50, 975–983.
- Presley, G., Smith, C., Hilsenroth, M., & Exner, J. (2001). Rorschach validity with African Americans. Journal of Personality Assessment, 77, 491–507.
- Rapaport, D., Gill, M., & Schafer, R. (1945). Diagnostic psychological testing: The theory, statistical evaluation, and diagnostic application of a battery of tests. Chicago: Year Book. (Revised Ed., 1968, R.R. Holt, Ed.).
- Raskin, J. (2001). Constructivism and the projective assessment of meaning in Rorschach administration. Journal of Personality Assessment, 77, 139–161.
- Ritzler, B., Erard, R., & Pettigrew, G. (2002a). Protecting the integrity of Rorschach expert witnesses: A reply to Grove and Barden (1999) re: The admissibility of testimony under Daubert/Kumho analysis. Psychology, Public Policy, and the Law, 8, 201–215.
- Ritzler, B., Erard, R., & Pettigrew, G. (2002b). A final reply to Grove and Barden: The relevance of the Rorschach Comprehensive system for expert testimony. Psychology, Public Policy, and the Law, 8, 235–246.
- Rorschach, H. (1921/1942). Psychodiagnostics: A diagnostic test based on perception. New York: Grune & Stratton.
- Rosenthal, R., Hiller, J.B., Bornstein, R.F., Berry, D.T.R., & Brunell-Neuleib, S. (2001). Meta-analytic methods, the Rorschach, and the MMPI. Psychological Assessment, 13, 449–451.
- Rossini, E., & Moretti, R. (1997). Thematic Apperception Test (TAT) interpretation: Practice recommendations from a survey of clinical psychology doctoral programs accredited by the American Psychological Association. Professional Psychology: Research and Practice, 28, 393–398.
- Rotter, J., Lah, M., & Rafferty, J. (1992). Rotter Incomplete Sentences Blank. San Antonio, TX: Harcourt Brace.
- Russ, S. (1993). Affect and creativity: The role of affect and play in the creative process. Hillsdale, NJ: Erlbaum.
- Schachtel, E. (1966). Experiential foundations of Rorschach’s test. New York: Basic Books.
- Schretlen, D. (1997). Dissimulation on the Rorschach and other projective measures. In R. Rogers (Ed.), Clinical assessment of malingering and deception (2nd ed.; pp. 208–222). New York: Guilford Press.
- Shedler, J., Mayman, M., & Manis, M. (1993). The illusion of mental health. American Psychologist, 48, 1117–1131.
- Shrout, P.E., & Fliess, J.L. (1979). Intraclass correlations: Uses in assessing rater reliability. Psychological Bulletin, 86, 420–428.
- Sloan, P., Arsenault, L., & Hilsenroth, M. (2001). Use of the Rorschach in assessment of war-related stress in military personnel. Rorschachiana (Journal of the International Rorschach and Projective Techniques Society), 25, 86–122.
- Stedman, J., Hatch, J., & Schoenfeld, L. (2000). Preinternship preparation in psychological testing and psychotherapy: What internship directors say they expect. Professional Psychology: Research and Practice, 31, 321–326.
- Stricker, G., & Healey, B.J. (1990). Projective assessment of object relations: A review of the empirical literature. Psychological Assessment, 2, 219–230.
- Timbrook, R.E., & Graham, J.R. (1994). Ethnic differences on the MMPI? Psychological Assessment, 6, 212–217.
- United States v. Frye, 293 F. 1013 (D.C. Cir., 1923).
- Urist, J. (1977). The Rorschach test and the assessment of object relations. Journal of Personality Assessment, 41, 3–9.
- Viglione, D.J. (1999). A review of recent research addressing the utility of the Rorschach. Psychological Assessment, 11, 251–265.
- Viglione, D., & Hilsenroth, M. (2001). The Rorschach: Facts, fictions, and future. Psychological Assessment, 13, 452–471.
- Wagner, E. (1983). The Hand Test manual (rev. ed.). Los Angeles: Western Psychological Services.
- Wechsler, D. (1997). WAIS-III/WMS-III technical manual. San Antonio, TX: Psychological Corporation.
- Weinberger, D. (1995). The construct validity of repressive coping style. In J.L. Singer (Ed.), Repression and dissociation: Implications for personality theory, psychopathology, and health (pp. 337–388). Chicago: University of Chicago Press.
- Weiner, I.B. (1996). Some observations on the validity of the Rorschach Inkblot Method. Psychological Assessment, 8, 206–213.
- Weiner, I.B. (2001). Advancing the science of psychological assessment: The Rorschach Inkblot Method as exemplar. Psychological Assessment, 13, 423–432.
- Westen, D. (1995). Social Cognition and Object Relations Scale: Q-sort for projective stories (SCORS-Q). Unpublished manuscript, Cambridge Hospital and Harvard Medical School, Cambridge, MA.
- Westen, D., Lohr, N., Silk, K., Kerber, K., & Goodrich, S. (1989). Object relations and social cognition TAT scoring manual (4th ed.). Unpublished manuscript, University of Michigan, Ann Arbor.
- Westenberg, P., Treffers, P., & Drewes, M. (1998). A new version of the WUSCT: The Sentence Completion Test for Children and Youths (SCT-Y). In J. Loevinger (Ed.), Technical foundations for measuring ego development (pp. 81–89). Mahwah, NJ: Erlbaum.
- Widiger, T., & Frances, A. (1987). Interviews and inventories for the measurement of personality disorders. Clinical Psychology Review, 7, 49–75.
- Wood, J.M., Nezworski, M.T., & Stejskal, W.J. (1996). The Comprehensive System for the Rorschach: A critical examination. Psychological Science, 7, 3–10.
- Wood, J.M., Nezworski, M.T., Stejskal, W.J., & McKinzey, R.K. (2001). Problems of the Comprehensive System for the Rorschach in forensic settings: Recent developments. Journal of Forensic Psychology Practice, 1, 89–103.
- Zilmer, E., & Perry, W. (1996). Cognitive-neuropsychological abilities and related psychological disturbance: A factor model of neuropsychological, Rorschach and MMPI indices. Assessment, 3, 209–224.
CHAPTER 24 Projective Tests: The Nature of the Task
MARTIN LEICHTMAN
INTRODUCTION 297 WHAT ARE “PROJECTIVE” TESTS? 298 Projection 298 Apperception 299 Alternative Processes 300 Empirical Definitions 301 THE PROJECTIVE TASK 302 THE STRUCTURE OF THE REPRESENTATIONAL PROCESS 303 The Symbol Situation 303
Addressor and Addressee 304 The Medium or Vehicle 306 The Referent 308 CONCLUSION 309 Similarities and Differences Among Projective Tasks 309 Approaches to Interpretation 309 Strengths and Limitations 310 The Future of Projective Tests 311 REFERENCES 312
INTRODUCTION
Like other psychological tests, projective techniques begin with a task. The task is given in a prescribed manner by one person who has license to do so to another who is to be assessed for some purpose. How the task is handled is then analyzed according to theories about its nature-utilizing procedures that typically involve categorizing, coding, and quantifying responses and comparing them with how other people have handled the task. On the basis of such analyses, inferences are made about personality and behavior. Yet, although it is the subsequent steps in the process—the theories, the scoring, the norms, and the inferences—upon which psychologists pride themselves and upon which their livelihoods depend, tests always begin with a task.
Such an observation will not come as news to readers of so sophisticated a text as this one. It is on the order of stating that you boil water by putting it on a stove and turning up the heat—so obvious as to hardly bear mention. Nonetheless, it is worth mentioning, if only because the obvious is all too easily ignored and, with it, much that is essential to understanding projective tests.
For example, the Rorschach test, long the most popular projective technique, has been the subject of an enormous body of literature on administration and interpretive procedures, clinical applications, and research on personality assessment and psychopathology. However, apart from the few pages that Rorschach (1921) devoted to articulating his view that the test was based on a particular form of perception, only a handful of works (Exner, 1986; Leichtman, 1996a, 1996b; Rapaport et al., 1945–1946: Schachtel, 1966) give serious attention to the nature of the Rorschach task itself. This neglect may well have contributed to the test becoming a rather esoteric instrument with a language and concepts that are isolated from the broader body of psychological theory. It also contributed to the paucity of explanations of why specific Rorschach scores mean what they are purported to mean. Hence, although the value of the Rorschach in assessing disordered thinking is well documented (Kleiger, 1999), little has been written about why Rorschach thought disorder signs are signs of thought disorder (Leichtman, 1996b).
Equally significant problems are present with regard to projective tests in general. Indeed, over the last 60 years, what such tests are and how they work has been the subject of continued, unresolved debates. When their popularity was at its peak, for example, Shneidman (1965, p. 498) began a comprehensive review by noting:
It would, of course, simplify the writing of this chapter—and considerably ease the reader’s task—if I could at the outset figuratively look the reader in the eye and say that projective techniques could be defined in such-and-such a way and were made up of such-and-such types and then simply follow this by giving a succinct definition and presenting a short, comprehensive classification scheme. But, of course, I cannot. And this is so primarily because the definition of projective techniques is a complex issue, and, even worse, the very concept and name itself pose a number of fundamental questions, which demand reflection and rethinking.
As Shneidman made clear, there was no consensus on their answers at the time. Nor, after several decades more of reflection and rethinking, are we closer to a consensus today.
Assuming that one reason for this state of affairs is that questions about the nature of the projective task have been passed over too quickly, this chapter is intended as an opportunity to reflect on them and to consider what such reflections contribute to answering other fundamental questions about projective tests. These questions include what unites these tests as a group, what differentiates them from one another, what general approaches have been adopted toward their interpretation, what inherent strengths and weaknesses are characteristic of them, and why, when so many concerns have been raised about their validity, reliability, and utility, they continue to have a claim on the interests of psychologists concerned with personality assessment.
WHAT ARE “PROJECTIVE” TESTS?
Projection
Coined in the 1930s, the term projective tests was derived from psychoanalytic concepts that were coming into prominence in intellectual, if not academic, circles in the United States. In the article in which they introduced the Thematic Apperception Test (TAT), Morgan and Murray (1935) noted that, as with the Rorschach test, “the process involved is that of projection—something well known to analysts.” Several years later Murray (1938) described the Rorschach, TAT, and similar instruments as “projection tests,” noting that they are
based upon the well-recognized fact that when a person interprets an ambiguous social situation, he is apt to expose his own personality as much as the phenomenon to which he is attending. Absorbed in his attempt to explain the objective occurrence, he becomes naively unconscious of himself and the scrutiny of others and, therefore defensively less vigilant. To one with “double hearing,” however he is disclosing certain inner tendencies and cathexes: wishes, fears, and traces of past experience. (p. 531)
In contrast to questionnaires, inventories, and other assessment instruments of the time, such methods were intended as techniques for making unconscious aspects of personality manifest.
The label was firmly established with Frank’s (1939) classic article “Projective Methods for the Study of Personality.” Although standardized tests of the period claimed to measure individual differences, Frank asserted, they, in fact, were quantified measures of how closely individuals approximated some social norm. Dealing with stimuli that appeared to have set objective meanings and eliciting responses affected heavily by convention and considerations of social desirability, such tests were deemed inadequate for the study of personality, the most significant aspects of which were subjective and often hidden ones that made individuals unique. Assuming personality to be a process of “organizing experience and structuralizing life space in a field,” Frank (1939, pp. 402–403) heralded a new class of tests that involved presenting an individual with
a field (objects, materials, experiences) with relatively little structure and cultural patterning, so that the personality can project upon that plastic field his way of seeing life, his meanings, significances, patterns, and especially his feelings. Thus we elicit a projection of the individual’s private world, because he has to organize the field, interpret the material, and react affectively to it.
Describing specific techniques briefly, Frank included, in addition to the increasingly popular inkblot tests, storytelling, play, art, drama, and music as other potential projective methods.
The sense in which projective techniques are “projective,” however, was always a source of discomfort for their proponents. To be sure, the linkage of the tests to psychoanalytic theory remained strong. In their review of the literature over the next two decades, Murstein and Pryer (1959) noted that discussions of the test, while only occasionally adhering to Freud’s concept of projection as a defensive operation, nonetheless used the term to characterize ways subjects attributed their own desires, feelings, and behaviors to others or at least ways in which needs and motives influenced perception. However, in Frank’s paper (1939) and others that soon followed (e.g., Abt, 1950; Bell, 1948; Sargent, 1945), efforts were made to link the tests to theoretical orientations such as Gestalt psychology, Lewinian field theory, organismic theory, and Allport’s personalistic psychology. These positions were united not by concerns about unconscious motivation but rather by opposition to empiricist and behaviorist perspectives that were believed to be too limited to capture the richness of the human personality. Equally important, almost from the first, those knowledgeable about psychoanalysis underlined differences between Freud’s concept of projection and the process underlying such tests. For example, Murray (1938), Rapaport et al. (1945–1946), Bellak (1950), and Lindzey (1961) stressed that, whereas the psychoanalytic concept designated a reality-distorting defense against unconscious wishes that was used by only some individuals, projective tests involved a universal process of attributing meaning to phenomenon.
As a consequence, advocates of projective methods strained to find broader connotations for the term. Rapaport et al. (1945–1946, p. 7), for example, suggested “The subject matter used in the procedure serves as a lens of projection, and the recorded material of elicited behavior is the screen with the picture projected on it.” Noting architectural and cartographic connotations involving reproducing features of a phenomena in different media, Bell (1948) concluded that projection was best characterized by its Latin roots, as a “casting forward” or “thrusting out,” implying the tests in some way involved outward manifestation of the internal characteristics of personality. Nonetheless, like Murray, who had come to regret the label, Bell was sensitive to the “deficiencies” of the term “projective tests.” The best arguments he could advance for maintaining it in his text were that “it does describe partially what takes place in the techniques . . . and has the advantage of carrying a significance through usage beyond the strict meaning of the term.” (p. 4). An additional reason for its continued use was that, although the term did not capture the essence of such tests, there was no agreement on alternatives that could do so better.
Apperception
One prominent alternative centered on the concept of apperception. Rorschach (1921) assumed that the act of perception is one in which stimuli are assimilated to an apperceptive mass, an organizational scheme shaped by the individual’s past experience. When the role of stimulus properties are reduced, as in the case of ambiguous or “chance forms” such as inkblots, he contended, the interpretive aspect of perception is highlighted, thereby making it possible to gain insight into the contributions of an individual’s personality to his or her experience of the world. Recognizing the multiple meanings that can be attributed to more structured visual material, Morgan and Murray (1935) were also strongly influenced by the concept in their development of the Thematic Apperception Test, as its very name indicates. After Frank (1939) stressed the ambiguous, unstructured quality of stimulus material in projective tests as a group, it was only a short step for Bellak (1950) to extend the concept of apperception to the class as a whole. Adopting Herbart’s definition of apperception as “the process by which new experience is assimilated to and transformed by the residuum of past experience to form a new whole,” he asserted that “all present perception is influenced by past perception, and that indeed the nature of the perceptions and their interaction with each other constitutes the field of the psychology of personality” (p. 11). Because of the ambiguous, malleable nature of their stimulus material, projective tests were ideal for examining the apperceptive process that individuals bring to the experience of the world. Within such a framework, Bellak contended, projection as a defense could be understood as an extreme form of “apperceptive distortion.”
The concept of apperception, however, is not adequate to capture the central process in projective tests. The attribution of meaning to unstructured or partially structured material is involved in some projective tests such as the Rorschach and TAT, but not in others. For example, “constructive techniques” such as drawing pictures consist of nothing more than providing subjects with a pencil and blank sheet of paper. Moreover, although a man and woman standing together in a TAT card may be seen as loving each other, hating each other, or being indifferent, the scene serves chiefly as a springboard for extended stories and characterizations that are critical in interpretation of the test. Even if a picture is taken to depict unrequited love, such themes have been the staple of Shakespeare and writers of soap operas and played by actors ranging from Laurence Olivier to Harpo Marx. The meaning attributed to the picture is only one component of the process of constructing a TAT story.
The designation of projective tests as chiefly those of apperception may be a case of an apperceptive distortion in which a diverse group of instruments have been assimilated to a powerful apperceptive mass, the Rorschach. Yet there are strong reasons for questioning whether the Rorschach itself is chiefly a test of perception or apperception (Leichtman, 1996a, 1996b). Perception theorists have long noted that the test is not chiefly concerned with the process they study (Zubin, Eron, & Schumer, 1965). Gibson (1956), for example, contends that
Although the reactions of a person to an inkblot are said to be indicative of an act of perception, this usage goes against the commonsense meaning of the term. From a strictly psychophysical and tough-minded standpoint, certainly, Rorschach reactions have little to do with perception” (p. 203)
The timetables for major transformations in how children handle the test are not correlated with changes in perceptual development of a magnitude that would account for them. The implicit assumptions underlying Rorschach inquiry and scoring—notably, that subjects are aware of the determinants of their perceptual processes and that there are typically one or perhaps two such determinants—would be scoffed at by

Figure 24.1 Card I and sketches of common responses. From The Rorschach: A Developmental Perspective (p. 124), by M. Leichtman, 1996. Hillsdale, NJ: The Analytic Press. Copyright 1966 by Analytic Press. Card I from Hermann Rorschach, Rorschach-Test. Copyright by Verlag Hans Huber AG, Bern, Switzerland, 1921, 1948, 1994. Reprinted with permission.
serious students of perception. The notion that the same stimuli might be perceived as vastly different things—a butterfly or pumpkin, for example—or that the utterly different stimuli on Cards I and V might be seen as the same thing (e.g., a butterfly) hardly accord with what is known of perceptual processes. Above all, Rorschach cards bear little concrete resemblance to objects with which they are presumed to make a good fit (see Figure 24.1). If Rorschach scoring of form was truly based on perceptual accuracy or good fit, as is often asserted, disparaged responses such as an inkblot, paint, or smudge of dirt would be the only acceptable ones, whereas such common percepts as bats or jack-o’-lanterns would hardly qualify for anything other than F-scores. Exner (1986) and Weiner (1986) have, in fact, acknowledged that “an inkblot” is the only correct response to the administration instructions of the Rorschach, but that such responses are not accepted. Instead subjects are expected to “misperceive” or “misidentify” the blot, “to see it as something that it is not.” In this regard, they return to the curious position advanced by Cattell (1951), who argued that the central feature of projective tests was the “distortion of a perception” and who accordingly labeled them “misperception tests of personality.”
From the standpoint of understanding the nature of projective tasks, however, this line of thought is far from satisfactory. A TAT card of a boy with a violin may elicit stories of a child daydreaming of being a great violinist in the hope of making his devoted parents proud or one who is furious at them for forcing him to practice the damned instrument while friends are out playing. In neither case has the subject “distorted” the picture or done anything other than tell a story about it that makes sense and is perfectly appropriate. Similarly, although Card I of the Rorschach bears a closer physical resemblance to a smudge of ink than a jack-o’-lantern, if asked what the card “looks like,” few, except for the intellectually limited, would give the former response in preference to the latter. Certainly rather than assuming an individual has misperceived the Rorschach card when he or she sees an original response, we are likely “see it” as well and be impressed with the accomplishment. With “good” projective test responses, we are not dealing with perceptual processes or any other processes that have gone awry, but rather with an achievement of some kind—and it is that achievement that an adequate conception of the tests must capture.
Alternative Processes
A variety of other processes have been identified as involved projective tests, but none, individually or in combination, provides the basis for a definition that encompasses the range of tests typically designated as projective instruments.
Not surprisingly, the concept of association, with its long pedigree in psychology, has been one such candidate. It provided the foundation for one of the first psychological instruments used to try to investigate personality, the Word Association Test. Early experimental studies using inkblot techniques also conceived of them as means of studying association (Parsons, 1917; Pyle, 1915). Rapaport et al. (1945– 1946) incorporated the concept into a three-stage, “cogwheel” theory of the Rorschach response process in which initial perceptual processing of the stimuli quickly gives rise to associations that organize responses that, in turn, are checked against perceptions of the stimuli. Going a step further, Lindzey (1961) classified the Rorschach as an association test. However, the power of the concept of association to explain projective tests as a group is limited because, at best, it applies only to some instruments. For example, in addition to tests based on association, Lindzey noted another four groups that centered on other processes.
Concepts of imagination and fantasy have also figured prominently in discussions of projective instruments. Morgan and Murray (1935), for example, advanced the TAT as “a method for investigating fantasies.” The assumption that fantasies are closely linked with unconscious wishes provided a foundation for the interest of psychoanalytically oriented psychologists in such instruments. The concept of imagination appeared suited to other techniques such as human figure drawing in which there are no overt stimuli to which the subject is expected to respond. And, even in the case of inkblot techniques, in which there are such stimuli, some have suggested that imagination is the key component of the response process. Several initial studies utilizing these methods conceived of them as means of studying visual imagination (Binet & Henri, 1895–1896; Dearborn, 1898) and some proponents of the Rorschach, notably Piotrowski (1950), emphasize its role in the test. Rorschach (1921) himself noted that subjects almost universally believe the test to be one of imagination, a belief he suggested that is almost a precondition for taking it. Yet Rorschach also denied that his instrument was chiefly a test of imagination, stressing instead the role of the stimulus and perceptual processes. Certainly, Rorschach scoring systems are based on coding and analyses of these characteristics. Hence, although imagination and fantasy undoubtedly play a role in most projective tests, that role varies with the test. Some, such as the TAT, strive to elicit fantasies; others like the Rorschach do not. Their centrality to the response process varies not only across tests but also across individuals.
Finally, projective tests have been viewed as tests of cognition. Although placing perception at the heart of the Rorschach process, Rapaport et al. (1945–1946), for example, were particularly interested in the organization and pathology of thought. Paying close attention to the ways in which Rorschach percepts are described and justified, they added a fifth scoring category, verbalizations, which were described as “a highway for investigating disorders of thinking” (p. 331). The role of thought organization was even more prominent in their interpretation of other projective tests such as the TAT. Similarly, Exner (1986), while stressing the role of perception in the Rorschach response processes, broadened that conception, describing the test at times as a “perceptualcognitive” or “problem-solving” task. Such a formulation can easily be extended to other projective tasks, all of which present problems to be solved via some form of cognitive activity. However, though no doubt correct, the position does not provide a basis for delineating projective tests as a group, since it is hard to think of any psychological test, projective or otherwise, that does not involve thought or cognitive processes.
Empirical Definitions
Perhaps because of problems of this kind, attempts to answer the question of what unites projective tests as a group on the basis of a common underlying process gave way to empirical approaches to definition. Analyzing instruments that were labeled “projective tests,” psychologists sought to articulate the characteristics of the class and identify subclasses of such instruments.
Frank (1939) initiated this approach, stressing that projective tests had two principal features: the use of media that were variously described as ambiguous, unstructured, and plastic and tasks in which there were a wide range of possible responses that were relatively free from social prescriptions, thus allowing for maximum expression of individual differences. He went on to note subtypes consisting of constitutive methods (e.g., the Rorschach) in which subjects impose structure on unstructured material, interpretive methods in which subjects express or describe what a stimulus situation means to them, cathartic methods in which the discharge of affect is primary, and constructive methods in which subjects arrange material according to their own conceptions. Noting the ambiguous or unstructured nature of the stimulus situation and the freedom subjects had in how to respond, White (1944) suggested a third critical quality, the subject’s lack of awareness of the intent of the examiner, which further maximized the range of responses. To these properties, Shneidman (1965) added characteristics related to test interpretation, in particular an interest in unconscious or latent aspects of personality and holistic analyses.
Carrying this approach furthest, Lindzey (1961) reviewed existing definitions of projective tests and identified primary attributes that are critical differentiating features of the instruments and secondary attributes that are found in many tests, but not all. Among the former, he included “sensitivity to unconscious or latent aspects of personality,” the range of responses permitted, assumptions that tests explored multiple aspects of personality, the subject’s lack of awareness of the purpose of the test, and the richness of the data provided. Among the latter, he listed the ambiguity of stimuli, holistic analysis, a tendency to produce fantasy responses, and the absence of right or wrong answers. On this basis, he defined a projective technique as
an instrument that is considered especially sensitive to covert or unconscious aspects of behavior, it permits or encourages a wide variety of subjective responses, is highly multidimensional, and it evokes unusually rich or profuse data with a minimum of subject awareness concerning the purpose of the test. Further, it is very often true that the stimulus material presented by the projective test is ambiguous, the interpreters of the test depend upon holistic analysis, the test evokes fantasy responses, and there are no correct or incorrect responses to the test. (p. 45)
He also classified such tests according to whether they were association techniques (e.g., the Word Association and Rorschach tests) in which a word or image is associated with stimuli, construction techniques (e.g., the TAT) involving the creation of an art form such as a story or picture, completion techniques (e.g., the Sentence Completion Test), choice or ordering techniques (e.g., the Wechsler Adult Intelligence Scale [WAIS] Picture Arrangement Subtest), or expressive techniques such as play, drawing, or psychodrama.
Although summarizing major qualities of projective tests noted in the literature, Lindzey’s definition is far from satisfying because it is an overly complex one in which it is hard to detect a central organizing principle. Yet the presence of some principle can be sensed, if only indirectly, from the fact that, like Frank’s subdivisions, Lindzey’s are far from distinct. One can question whether the Rorschach is really an association technique or whether expressive and constructive techniques truly differ from one another. Certainly subgroups tend to overlap and merge. The need for clarity alone warrants continuing Shneidman’s pursuit of a simple, succinct definition of projective techniques that recognizes what distinguishes them from other tests, differentiates them from one another, and shapes general approaches to their interpretation.
THE PROJECTIVE TASK
At this point it may be useful to set aside much of what we know about these psychological instruments and their interpretation and reconsider the nature of the task in projective tests. Perhaps the best way of doing so, and in the process grasping the essence of that task, is to adopt a naive approach to the problem and ask: Were these school tests, what kinds of classes would help students do well on them?
When we do so, it can be seen that “objective” tests, such as those of intelligence and achievement, warrant that appellation not only because of the manner in which they are constructed and the ways in which data are interpreted but also because of their subject matter. They assess the skills and information needed to deal with the physical and social environment. They focus on attention, concentration, perception, reasoning, and memory as well as acquired abilities such as reading, writing, and arithmetic. They also examine mastery of organized bodies of knowledge about aspects of the world. The Wechsler Intelligence Scale for Children—III (1991), for example, includes questions about astronomy (“In what direction does the sun set?”), anatomy (“How many ears do you have?”), geography, history, and political science, not to mention social customs and mores (“What is the thing to do if a boy/girl who is much smaller than you starts to fight with you?”). Such tests are concerned with how individuals handle particular types of symbolic forms, those that comprise the methods and modes of thought of the sciences (Cassirer, 1944).
Objective tests of personality and psychopathology often resemble a meeting with the school nurse or counselor in which students or their parents are asked to provide information about their history, interests, attitudes, or health. Some involve relatively straightforward questions about skills or symptoms (e.g., what hurts and how much). Others mix questions in seemingly random ways to minimize dissembling, with answers later rearranged and grouped according to different domains of interest to the nurse or counselor. But, by and large, the assumption underlying these instruments is that individuals can be relatively factual observers of their own states, behavior, and history.
Preparation of students for the best recognized projective tests would take a very different form. After all, when we administer the Human Figure Drawing, Kinetic Family Drawing, or House-Tree-Person tests, we are commissioning sketches on various themes. With the TAT, Children’s Apperception Test (CAT), and similar instruments, we are requesting short stories and, in the case of the Sentence Completion Test, very short stories indeed. Rather than obtaining factual information about an individual’s history, the Early Memories Test (Mayman, 1968) is an exercise in autobiography or “creatively constructed fantasies about the past” (Bruhn, 1990, p. 5). Similarly, most of the now forgotten projective methods suggested by Murray (1938) and Frank (1939)—dramatic productions, music reverie, modeling clay, and painting involve forms of creative expression. At their core, projective tests are concerned with the methods and modes of representation of the arts (Cassirer, 1944).
The prime seeming exception to this formulation is the Rorschach, an exception of particular significance because the instrument is often viewed as the quintessential projective technique. As has been seen, Rorschach and his leading followers viewed the task as one involving a complex perceptual process. Consequently, beginning with Frank (1939), those who conceptualized projective tests made distinctions among their types, some of which centered on perception or apperception and others of which involved expressive or constructive activity.
Yet the Rorschach is, in fact, similar to other projective tests. The overriding task it sets for subjects is not one of perception. Rather it consists of a representational act, that is, one in which material of some kind is shaped to depict or stand for an object or concept (Goodman, 1976; Olson & Campbell, 1993; Perner, 1991; Pratt & Garton, 1993; Werner & Kaplan, 1963). Subjects are given a medium, the inkblot, and required to make it stand for something, a process not unlike that of a sculptor carving designs out of marble. Perception plays a role in this process—subjects must process visual stimuli in order to make use of them in this way—and association enters in as well, suggesting referents to be depicted. Yet both processes are components of a superordinate process and their functions are determined by the overriding intention to form a representation.
When the Rorschach is conceptualized in this way, the problems that plague perceptual theories of the test evaporate (Leichtman, 1996a, 1996b). With a perceptual task, for example, one would expect there to be a single response that the stimulus actually looks most like, a notion that is anathema to any serious proponent of the Rorschach. In contrast, in representation, even a simple stimulus such as a curved line can “look like” utterly different concepts (e.g., a hill, a breast, the St. Louis Arch, or the changing values of a bogus gold mine stock over time). Conversely, different stimuli can stand for the same concept. One may give the response of “fire” on three different Rorschach cards—in one case on the basis of a shape that looks like flames, in another on the basis of the red color, and in still another because of the black shading. Methodological objections to the use of the Rorschach inquiry process to specify determinants also disappear. Whereas perception is determined by a multiplicity of stimuli of which subjects may be unaware, it makes perfect sense to suggest that a single feature—shape, color, or shading—is the basis for a representation. Moreover, because representation is a process shared with an audience, and thus has
public aspects, questions about scoring are minimized. If a subject asserts that a figure “looks like” an elephant because of a prominent trunklike shape that the examiner sees as well, there are few grounds for questioning that this feature was the primary basis for the representation, especially when no other aspect of the designated area is in any way elephantlike. No less important, whereas it is difficult to account for developmental changes in the Rorschach responses of children on the basis of perceptual theories, the point at which children first give Rorschach responses and the nodal points at which there are major transformations in the form and content of their responses are those at which there are widely recognized changes in qualities of their representational processes. Developmental changes in the handling of the Rorschach task, for example, correspond closely with analogous ones in other forms of visual representation such as drawing.
In sum, what links the Rorschach and all major projective instruments is simply that the task they set is the production of some form of artistic representation and that, for all the sophistication and diversity of their interpretive procedures, each in its own way is an attempt to infer from the form and content of these productions psychological characteristics of their creators.
THE STRUCTURE OF THE REPRESENTATIONAL PROCESS
The Symbol Situation
How such forms of creative expression are produced and interpreted can be understood in terms of four basic components of the representational process highlighted by Werner and Kaplan (1963) in their model of “the symbol situation” (Figure 24.2). Because representation requires that a medium be shaped to symbolize an object, action, or concept, the poles of the horizontal axis consist of the symbolic vehicle on one side and the referent or that which is to be represented on the other. Recognizing that representation also always involves somebody communicating something to an other or others, even when the dialogue is purely internal, the poles of the vertical axis consist of the addressor (the self, the artist, etc.) and the addressee (the other, the audience, etc.). Placing the components on axes allows for depiction of a development process in which progressive differentiation and hierarchic integration in symbolization are denoted by increasing distance between the poles. For example, in early language development children use simple words and primitive grammatical structures, the understanding of which requires their parents to be closely attuned to their feelings, thoughts, and
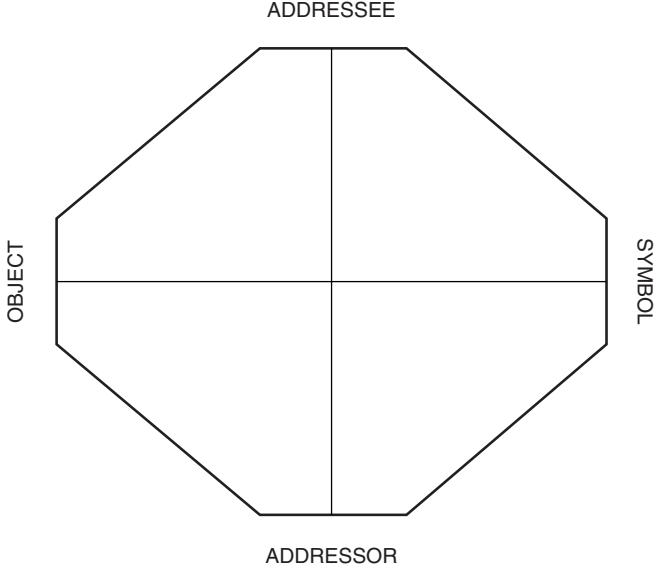
Figure 24.2 The symbol situation. From The Rorschach: A Developmental Perspective (p. 160), by M. Leichtman, 1996. Hillsdale, NJ: Analytic Press. Copyright 1966 by Analytic Press. Reprinted with permission.
environment; with development increasingly complex forms of language are used in ways that communicate increasingly complex thoughts to others who may have little idea of the immediate context in which events occur. Conversely, the emergence of severe pathology, especially signs of thought disorder, can be seen to involve dedifferentiation and “disintegration” in the process of representation.
Addressor and Addressee
Although discussions of projective tests focus chiefly on components along the horizontal axis of the model, and especially on what subjects choose to represent, test responses, whether Rorschach percepts or TAT stories, are formed within a social context and neither their form nor content can be understood fully without taking both objective and subjective aspects of that context into consideration (Holt, 1978; Schachtel, 1966; Schafer, 1954).
In critical respects, those who suggest that a major defining characteristic of projective tests is that subjects are unaware of the purpose of the tests and how they will be interpreted are wrong. The assessment process, in fact, presupposes that the psychologist and client play prescribed social roles of tester and testee of which they are all too aware. Spelled out in test manuals and inculcated as part of professional training, the psychologist’s role consists of administering test tasks in standardized ways; dealing with resistances to or difficulties understanding those tasks; providing a receptive atmosphere that encourages optimal performance; and interpreting results according to a set of formal procedures. The role of testee consists of accepting that one has come for testing for a purpose (typically evaluation of psychological problems that interfere with handling critical aspects of life), acknowledging the psychologist’s authority to define the tasks to be undertaken, and recognizing that the tests will be interpreted in ways intended to understand one’s problems and make recommendations about ways in which they can be addressed. In the case of projective tests, subjects know that they are to make up stories, draw pictures, or tell what inkblots look like and that the responses they give will be used to form impressions of their personalities and behavior. As a consequence, they sense that their productions and the very act of producing them are forms of communication about themselves and their problems.
If both parties accept their roles, a framework is established for the production of particular types of symbolic forms and more often than not psychologists, taking the testing relationship for granted, focus their attention on test responses alone. If subjects have difficulty with their role, psychologists may modify test procedures to varying degrees to obtain information, but then must make judgments about whether the modifications are of a magnitude that invalidate interpretation of test results on the basis of standardized norms. In such cases, subjects may be labeled “untestable,” although from a clinical standpoint a good diagnostic picture can be developed often through examination of how and why procedures have been modified or even why a patient refuses to participate in an evaluation altogether (Kaplan, 1975; Leichtman, 1995; Leichtman & Nathan, 1983). For example, if a man gives no responses to the Rorschach because he is convinced that the psychologist is conspiring with the CIA and unnamed foreign powers to destroy him, we may already have learned most of what is essential for arriving at a diagnosis and planning treatment.
Yet it is not just paranoid individuals who define the test situation in their own ways; the process is universal. Although personal or subjective definitions of the test relationship seldom override the objective roles participants play, they are nonetheless present at all times. Just as if the testing relationship were a TAT card of themselves and a tester at work, subjects construe their roles and those of examiners in their own distinctive ways (Leichtman, 1995). From the first, in their dress, their manner, their experience of examiner, and their attitudes toward being evaluated, they seek to define themselves and others and cope with concerns about how they will be seen. Effective testing, in fact, requires an intuitive appreciation of this fact. As Terman and Merrill (1960) observed even with regard to administration of the StanfordBinet Intelligence Scale, establishment of rapport is not simply a matter of behaving in a benign, supportive way; it is a complex process that assumes innumerable forms. Typically, it consists of a host of subtle, often unrecognized behaviors (e.g., one’s tone of voice, posture, pacing of testing, decisions about when to be supportive or confrontational or how far to carry inquiries into questionable responses, and so forth). Yet when such behavior is reflected upon, psychologists find that what is called “rapport” has involved adoption of roles and attitudes that are reciprocal to those of their clients. In testing an anxious little girl, experienced testers may act like a soothing parental figure, whereas with a delinquent boy they are more likely to feel like a parole officer or drill sergeant. It is the influence of the tester, by virtue of such behavior and even his or her appearance, on the subject’s experience of the test situation that provides the foundation for explanations of examiner effects on performance of psychological tests of all kinds (Jensen, 1980; Masling, 1960, 1966).
Although the subjective experience of this relationship plays a role in all testing, its impact on projective tests is especially pronounced because of the nature of their task. If one compares solving an arithmetic problem or answering a factual question with writing a short story, for example, it is clear that the former are relatively impersonal whereas stories are tales told to someone (even oneself) for a purpose. They are produced for an audience. The former have an objective focus and often consist of recall of public information; the latter is far more subjective, because to create a story authors draw upon their own feelings, experiences, and fantasies. The former tasks are accomplished by applying a set of welldefined procedures, whereas in producing a story wide leeway is granted in the use of narrative forms and conventions governing choices of content. Objective tasks have a limited number of clear-cut solutions and how those solutions will be judged is familiar; artistic productions can take innumerable forms and their reception by critics is uncertain. In short, how one experiences and seeks to define oneself and how one experiences real and imagined audiences are integral to the production of creative representations in general—and their influence is magnified further when artists, often in the midst of personal crises, know that their audience will analyze their work to make judgments about their personality and character and recommendations that may significantly affect their lives.
The profound influence of the experience of self and other on test productions can be seen in any number of ways. One is the striking developmental changes in the content of Rorschach responses of young children. Preschoolers often give charming, imaginative responses such as boonjis, schniatzs, and pink sissers, fireplaces with feet or chickens with two
heads, bears ready to attack them, and even cows that have walked onto cards but subsequently walked off (Allen, 1954; Ames, Learned, Metraux, & Walker, 1952). By early elementary school years, such responses disappear in normal children, to be replaced by less interesting, reality-bound percepts with locations that can be easily determined. Confabulations, incongruous combinations, and idiosyncratic responses now become signs of pathology (Klopfer, Spiegelman, & Fox, 1956). The reason for such changes lies in the fact that, now capable of concrete operations, school-age children have a heightened sense of how they may be viewed by others. Concerned with being seen as immature and wishing to avoid ridicule, they limit the range of responses they allow themselves to produce and put considerable effort into trying to be “realistic,” a phenomenon also encountered in their artistic productions and behavior in general (Gardner, 1980, 1982). In a similar vein, the reasons blatantly sexual, aggressive, and even bizarre Rorschach responses in adults are associated with poor reality testing and significant pathology have as much to do with their authors’ judgments about how they are presenting themselves and about the nature of their audience as with the content of the response themselves. For example, if the Rorschach were being used to award a lucrative contract to write the script of a horror movie or X-rated film, we would not be surprised if subjects “saw” a great many more gory percepts or ones involving human beings engaged in unnatural acts than current statistical tables would suggest.
The manner in which the experience of addressor-addressee is manifested in the clinical situations can be illustrated through a fictional example. In the seldom-performed 12th scene of A Streetcar Named Desire, a fading Southern belle has been brought to a sanitarium following a traumatic experience with her brother-in-law. There, a young psychologist asks her to look at a number of inkblots. To the fifth she responds: “It’s a butterfly, a fragile and exquisite creature that once roamed free, but now, is caught in the net of a naturalist. It will be pinned down and studied with a cold eye by a man who has no sense that it was once a living, breathing, vibrant being.”
Three aspects of such a response are of particular significance for the present purposes. First, as with all art, the very manner in which a work is presented constitutes a kind of performance. The rich, emotion-laden nature of the response and no doubt the affect evident as it is given suggest that Ms. D. strongly wishes to be seen as a refined, deeply sensitive woman and to establish an immediate intimate relationship with even an unfamiliar audience to whom she will pour out her innermost thoughts and feelings. Second, such wishes affect the style of the response itself. Predisposed to
a lush romanticism, she presents even the seemingly most mundane of popular responses on the Rorschach in a dramatic, flamboyant, fantasy-laden manner. Finally, there are strong suggestions that the content of the response is shaped by her sense of herself and others and may reflect significant events in her life. Even though the configuration of the card leads many respondents to see it as a butterfly, that image accords far better with Ms. D.’s experience of herself than a moth or bird, responses that fit equally well. More important, the quality of the elaboration, notably the attribution of characteristics such as delicacy, sensitivity, and refinement, suggest that the response incorporates qualities she wishes to ascribe to herself and, in fact, seems to be enacting as she gives it. In addition, the theme might well raise questions about whether the problem that led her to the sanitarium was a trauma involving being “pinned down” and violated by an overpowering male and that the violation was not only physical but also consisted of a critical scrutiny that stripped away all that gave her life meaning. At the very least, some of the parallels between the naturalist and the tester might suggest that although Ms. D. professes a readiness to depend on the kindness of strangers, she in fact has a profound distrust of others’ intentions that will pose particular challenges for the treatment process.
Although chosen for dramatic effect, such an example highlights critical features in all projective test responses. In every case, these responses consist of work presented to an audience. Even when subjects go to the opposite extreme of Ms. D., behaving in the most self-effacing or guarded ways, how they wish to appear, what they wish to display and to hide, and the manner in which the audience is experienced affect their responses. Such variables affect the content of their productions in the sense that, in order to make imagined worlds come alive, as in creating a convincing story, writers must draw on their own experience, feelings, and fantasies. And even when they do not and instead try to rely on mundane conventions, they still must make choices among a variety of conventional responses. Moreover, how one wishes to present oneself to an audience enters into the style of a work of art as much as its content. Whereas Ms. D. prefers high drama and romance, others might seek to demonstrate through their style that they are as macho as Hemingway, as refined as Proust, or as bright but self-deprecating as Woody Allen. They may seek to accentuate how realistic, whimsical, satiric, melodramatic, or even ordinary they can be. In effect, the very nature of the creative process is such that one’s sense of self and one’s audience enters into all aspects of artistic representations.
The Medium or Vehicle
All projective tests involve the use of media that are shaped to form representations. For example, a charming test for children simply asks them to choose animals they would most and least like to be and that most resemble them and members of their family. Recognizing that they are not being interviewed for positions in a zoo or on a farm, they select ones that have qualities that they wish for or repudiate or that they believe share characteristics with them or their family. Animals, with their range of physical attributes, behaviors, habitats, and roles in popular lore, are material for creating a metaphor. In other projective tests subjects are asked to use language and narrative forms to portray imaginary actions of figures in a picture or make lines on paper to depict people. In each case, material of some kind is transformed into a symbolic vehicle that stands for a concept.
There is perhaps no projective method in which the significance of the medium is greater than the Rorschach, the technique that has contributed the most confusion to discussions of its role. Because of its prominence, Frank (1939) and most others who tried to conceptualize projective tests followed Rorschach’s lead and stressed the role of “ambiguous” or “unstructured” stimuli in all of these instruments. However, far from being ambiguous or unstructured, as Schafer (1954, p. 114) observes, Rorschach cards
have definite, easily perceivable shapes, colors, textures, and configurations. In other words, if we did not leave patients on their own, but simply asked them direct, detailed questions about these properties of the blots, they would manifest little individual variability of response, except perhaps in style of verbalization.
What most distinguishes the blots is another quality that Frank linked with ambiguity but which is fundamentally different: plasticity. Each, with its distinctive shapes, colors, textures, and configurations, provides material that can be molded in thousands of ways.
The primacy of this property of Rorschach cards can be seen in a number of ways. As Piotrowski (1981) observed, most who administer the test intuitively believe certain Rorschach cards are “better” than others. If allowed to give only one inkblot, few would choose Card V in preference to Card I. The latter is a “good” card because its complex shape, open spaces, and shading allow it to be molded into far more responses than the former, which, because it is simpler and contains a prominent winglike shape, yields a high percentage of popular responses. Such judgments of the quality of the cards are, in effect, based on their plasticity. An even more dramatic example of the importance of this quality is the fortuitous accident that led to the current set of blots. The variegated shading of Rorschach cards was not present in Rorschach’s original material, but grew out of a printer’s error during publication of Psychodiagnostics. Rather than being outraged that shoddy work threatened to violate the integrity of his experiment, Rorschach immediately appreciated that the shading increased the creative possibilities of the test, and it has been part of blots ever since (Ellenberger, 1954). The test owes its prominence to this property—to the extraordinary richness of inkblots as a creative medium.
Recognizing the role of the structuring of the medium in projective tests is essential to understanding critical aspects of their interpretation. In offering a rationale for projective tests, Frank (1939, p. 402) argued that the manner in which subjects give meaning to material that is relatively unstructured and not subject to “cultural patterning” reveals their distinctive ways of “organizing experience and structuralizing life space in a field.” Yet, the mechanism by which such “projection” occurs is not readily apparent. In contrast, when projective tests are viewed as forms of representation, it becomes clear. Because human experience is organized through representational processes, how individuals shape a broad range of symbolic media in a variety of situations would be expected to yield insight into their characteristic modes of doing so.
As a consequence, although interpretations of projective tests often center on the content of responses, in some cases, their greatest potential lies in their contribution to understanding modes of symbolization. For example, when human figure drawings are considered in terms of formal characteristics, estimates of intelligence in children can be based on the degree of differentiation (e.g., the number of features included) and integration (e.g., the relationship of parts and proportionality) of the figures drawn (Harris, 1963). Leaving aside the themes of TAT stories, we can learn much of importance by considering the coherence of narratives, the complexity and quality of characterizations of people, and the genre chosen (e.g., whether we are dealing with comedy or tragedy, farce or melodrama, realism or soap opera, and so forth).
Of all projective tests, analysis of modes of symbolization plays the greatest role in Rorschach interpretation. Most basic Rorschach scores, notably those for “location” and “determinants” (e.g., form, color, or shading), codify how the medium is shaped to form a vehicle for representation. Indeed, only when determinants are conceived in this way can a sound rationale for their meaning be offered. For example, because whole responses typically require handling the medium in ways in which there is both differentiation and integration of
their parts, it is reasonable to assume that individuals who represent experience in this way display greater cognitive sophistication and intellectual ambition than those who give a preponderance of simpler large detail responses. Similarly, individuals who give small or rare detail responses tend to represent the world in far more idiosyncratic ways than the former two groups, who handle the medium in a conventional manner. Certainly, explanations based on ways of representing experience make better sense than those that imply these groups actually “see” visual stimuli differently.
Recognition of how media are handled in the representational process is even more important in providing a rationale for Rorschach thought disorder signs (Leichtman, 1996b). Efforts to explain why form quality provides a basis for inferences about “reality testing” on the basis of perceptual theories (e.g., “good” form is a sign of “perceptual accuracy”) are far from satisfactory. As has been seen with Figure 24.1, there is little concrete resemblance between Rorschach responses and pictures of objects with which they are said to make a “good fit.” Moreover, leading Rorschach scoring systems (e.g., Exner, 1986) have, in fact, abandoned the notion that examiners can rely on judgments of accuracy and instead base determination of form quality on the frequency of responses in normative samples. In contrast, when considered from the standpoint of use of representational media, four criteria for assessing the quality of forms, each bearing a clear relationship to “reality testing,” can be specified (Leichtman, 1996b). Individuals who represent experiences in terms of their most salient features, include a variety of features simultaneously, integrate them into more complex, coherent representations, and exclude from those representations extraneous or inappropriate characteristics tend to be judged to be more attuned to reality than those who do not. Other Rorschach thought disorder signs such as incongruous combinations, fabulized combinations, and confabulations in which the blot serves as little more than a springboard for elaborate fantasies also reflect problems with the use of the medium and its coordination with the referent. For example, in the most pathognomonic Rorschach thought disorder indicator, the contamination, subjects give responses such as “a butterflower” in which the medium ceases to be treated in distinct, stable, articulated ways (the same area simultaneously represents two different concepts) and there is a radical dedifferentiation of symbol and referent as concepts merge with one another. From the standpoint of symbolization, such responses are not curious phenomena confined to Rorschach alone. Rather, they may be seen to be the equivalent with regard to visual representation of the neologism, and, in fact, subjects often need to coin neologisms to describe such responses.
Although so obvious that little comment is warranted, consideration of the nature of the symbolic vehicle used is also a critical feature in differentiating projective tests from one another. Each medium differs in its possibilities and limitations, the rules governing its use, and the degree to which it is familiar to subjects and they can rely on conventional patterns of usage if they choose. As a consequence, each can make unique contributions to assessment, as can comparisons of similarities and differences in the representational processes in different circumstances.
The Referent
All projective tests require choices of what is to be represented. It is these referents—the person depicted in the Human Figure Drawing, the themes of the TAT, the early memories of the Early Memories Test, and the content of Rorschach responses—that constitute the subject matter of most analyses of projective tests. It is in the breadth and types of choices they allow with regard to this aspect of the projective task that tests most differ from one another.
The Rorschach can be placed at one end of a continuum in the sense that it allows the broadest choice referents. Subjects are, in principle, free to make the blot into anything they wish, the only constraint being the limits of what the medium lends itself to depicting. This fact, in turn, has a substantial bearing on test responses and their interpretation. For example, psychologists often wish to use this test, like others, to assess how subjects experience themselves and significant figures in their lives. Yet the overt task gives little clue that this is being done or how psychologists will go about doing so. As a consequence, subjects have difficulty shaping their responses to create a specific impression. As Schafer (1954) notes, the ambiguity in Rorschach is not in the blot but rather in subjects’ uncertainties about what will be made of their responses. At the same time, the lack of specificity of the task also affects the kinds of inferences that psychologists can make from the test and the degree of assurance with which they can do so. Relying on indicators such as whether human beings appear at all among test responses, whether actions are ascribed to these figures, and, if so, what types of actions—psychologists are most comfortable offering conclusions about general attitudes and dispositions and, often, least comfortable doing so about specific relationships, such as those with a mother or father.
Although the TAT literature initially stressed the ambiguity of the cards and the range of ways in which they can be construed, what differentiates TAT most from Rorschach is that its task has a far greater degree of specificity of content. Because subjects are required to make up stories about human beings engaged in some kind of action, TAT productions are likely to have a more direct bearing on how individuals experience themselves and others. Moreover, the scenes depicted in individual cards set limits on the content of stories about them. Only certain themes are appropriate for a picture of a man standing beside a half-naked woman in bed or a younger man beside an old woman. At the same time, within those limits considerable variation is possible. A dark figure in a graveyard may provide the starting point for stories that center on themes of mourning, fear, or aggression and have main characters ranging from kindly figures expressing their care for others to monsters wishing to wreak havoc on mankind. However, while the greater specificity of the task gives examiners more control over the material they elicit, it also gives subjects a better idea of what testers are assessing. Most have some sense that their descriptions of figures in pictures will be taken as a reflection of their own lives, motives, and relationships. As a consequence, they have greater ability to shape responses to create particular impressions.
Within the class of storytelling tests, psychologists have a substantial influence on the referents chosen through their selection of the material that sets the task. Because of the ambiguity of many of its pictures and the seemingly random nature of their selection, the TAT gives subjects wide latitude in deciding on themes. On one hand, these qualities allow inferences to be made on the basis of these choices, but, on the other, they may not elicit material systematically on particular issues of interest to psychologists. In contrast, stories about CAT cards, such those of chicks eating with a older chicken in the background, two large bears and a cub engaged in a tug-of-war, or a puppy being spanked by a parent in the bathroom, are likely to produce stories about the handling of typical childhood conflicts and relationships with family members. In a similar manner, the Michigan Pictures Test (Hutt, 1980) depicts school-age children in a variety of common situations with peers and family. Other tests use pictures more closely tied to specific themes. The Blacky Pictures (Blum, 1949), for example, are intended to obtain material bearing on the handling of Freudian psychosexual conflicts. Still other tests are even more narrowly focused, such as the Rosenzweig Picture Frustration Study (Rosenzweig, 1960), the Separation Anxiety Test (Hansburg, 1986), or the School Apperception Method (Solomon & Starr, 1968), the intended subject matter of which can be inferred from their titles. As the range within which choices of referents can be made is limited, greater sampling of material on topics of interest is possible, but subjects also have more control over the impressions they create.
Referents of tests can be made more specific in other ways. With all storytelling tasks, psychologists must rely on an extended chain of inferences to link test data to experiences of oneself or others. The tasks, after all, call for making up a story. As with most fiction, autobiographical elements may be woven into narratives, but subjects who literally describe themselves and incidents in their lives override the task and psychologists are strongly inclined to suspect narcissistic character traits. In contrast, the Early Memories Test (Bruhn, 1990; Mayman, 1968) calls for referents directly linked to self-experience and relationships with family members, although it continues to allow a degree of distance in the sense that what is sought is a selection among memories from childhood rather than current experience. The Animal Choice Test sets the most specific task in this regard by requiring metaphors characterizing current aspects of oneself and family members. At the same time, the very specificity of the referent gives subjects a clear sense of what the examiner is about and the most control in tailoring responses to create impressions.
In effect, what differentiates projective tests most from one another is the range and types of referents they are designed to elicit. In addition, although Lindzey (1961) and others are correct in noting that, as a class, projective tests are distinguished by subjects having a limited sense of how their responses will be interpreted, there is, in fact, substantial variation among instruments on this dimension. As a rule, the more specific the test’s focus, the more sense subjects have of what psychologists are interested in and the more they consciously mold responses to influence impressions. This balance leads to differences in interpretive procedures across tests but allows for comparison of inferences based on data obtained in varied circumstances.
CONCLUSION
Similarities and Differences Among Projective Tests
Understanding the nature of their task provides a basis for answering fundamental questions about projective tests and their use, foremost among which are what distinguishes these instruments as a group and what differentiates them from one another. As has been seen, what unites the class is the task itself. At their core, each of the major projective instruments requires production of some form of artistic representation making up a story, drawing a picture, constructing part of an autobiography, creating a metaphor, molding inkblots to depict concepts, and so forth. As a consequence, although the
interpretive procedures used to analyze this data vary considerably, each, in its own way, is a procedure for reading back from the form and content of creative representations and how they have been produced to psychological characteristics of their creators.
Because representation always involves shaping material to stand for an object or concept, the nature of the projective task also provides a basis for recognizing critical distinctions among these instruments. In particular, tests differ with regard to their media (e.g., whether they deal with types of linguistic or visual forms), each of which has its own qualities, potentials, and limitations. They also differ in the range and type of referents they elicit. For example, whereas Rorschach responses can be anything, responses to the Animal Choice Test are expected to be limited to those embodying salient attributes of oneself or family members. Whereas one figure-drawing task may call for the depiction of any human being whatsoever, another is restricted to representations of oneself and one’s family. The features that most distinguish projective tests from one another are differences along these two dimensions.
Approaches to Interpretation
Tests, of course, only begin with such tasks. Once representations are produced, they must be analyzed, and it is here that the theories, coding systems, normative data, and interpretive rules that comprise the tests come into play. Nonetheless, insofar as methods and theories must be applied to data of a specific kind that are gathered in specific ways, appreciating the nature of a task has much to contribute to understanding approaches to its interpretation. For example, among the primary attributes of projective tests is that they are “highly multidimensional” (Lindzey, 1961, p. 45). When viewed from the standpoint of the components of the representational process, the most salient of those dimensions become clear.
Because representations always involve one person communicating with another, one critical set of dimensions is the experience of self and other in the test situation. As has been seen, such variables affect all tests and have been the subject of extensive research on examiner effects on performance even with intelligence tests (Jensen, 1980; Sattler, 1988). However, their influence is many times greater with projective tests because the tasks call for imaginative and creative activity rather than applications of acquired skills to objective problems, because of uncertainty about how productions will be judged, and because by their very nature artistic representations are always shaped by a relationship to an audience. The effects of such relatively uncontrolled variables contribute substantially to the psychometric concerns raised about projective instruments.
Two approaches to Rorschach interpretation illustrate alternative interpretive strategies that have been adopted to deal with this situation. The predominantly nomothetic position represented by Exner (1986) seeks to minimize the effects of these variables by stressing strict adherence to standardized administrative procedures, focusing on aspects of the test least likely to be affected by subjective construals of the test situation (e.g., the use of medium) and relying heavily on scores and norms. In contrast, the clinical approach associated with the Rapaport tradition (Berg, 1986; Lerner, 1991, 1998; Schachtel, 1966; Schafer, 1954, 1967; Schlesinger, 1973; Sugarman, 1981) views testing as a standardized interview in which variations in how subjects experience themselves and others are treated as valuable sources of information, especially with regard to manifestations of transference and countertransference that are likely to recur in psychotherapy. While not abandoning the use of scoring and norms, those adopting this approach pay careful attention to behavior in the test situation and responses that bear on the testing relationship and inquire into such matters in the course of the evaluation. Each strategy has its own merits and drawbacks, and most clinicians use some combination of the two. For the present purpose, what is important is not which is best or how they should be balanced, but rather recognition that each approach is a way of dealing with problems and opportunities inherent in interpersonal aspects of the representational process.
Another critical component of the projective task is how media are shaped in the creation of symbolic forms. The capacity of projective tests to highlight this aspect of representation, not to elicit projection or any other reality-distorting process, offers the strongest rationale for claims of providing means to assess how human beings give form to their experience. As noted, Rorschach scoring systems are focused largely on modes of symbolization. Although less prominent in the interpretation of other projective instruments, the nature and quality of representations can nonetheless be important in each. For example, they provide the basis for making inferences about intelligence from human figure drawings or about thought organization from TAT stories. In addition, because measures of how media are used center on the form of thought, they are less subject to manipulation by subjects and exhibit more stability than those related to its content.
Finally, all projective tests involve choices among referents. It is this aspect of the task that has been the focus of most interpretative schemes, although these schemes are determined less by the projective task than by theories of personality and preferences for particular analytic techniques. Nonetheless, two aspects of the task have an important bearing on interpretation. First, the referents of most projective tasks are real and imagined people who are often engaged in interactions with one another. The material thus produced concerns how individuals represent themselves and others, what motives and attitudes are most salient in their interactions, and what emotions predominate. As was recognized from the first (Frank, 1939), such data provides an invaluable window from which subjective experience can be studied. Second, by their very nature, creative representations invite a broad range of interpretive procedures in analyzing their content. They may be subjected to psychometric analyses similar to “objective” instruments, such as Exner’s approach to the Rorschach; their resemblance to material arising in an expressive psychotherapy process makes it natural to adopt clinical techniques, such as the model drawn from Freud’s interpretation of dreams that Holt (1978) applies to the TAT; or they may be approached as aesthetic productions. Because the arts give expression to artists’ distinctive visions of their worlds, from the first, clinical tasks centering on them have attracted the interest of psychologists invested in idiographic approaches to the study of personality as well as those with nomothetic orientations.
Strengths and Limitations
Proponents and critics of projective tests have long debated their merits. Reviewing main points made by each, Kline (1993) noted that frequently cited weaknesses of projective tests include issues of reliability, validity, contextual influences on test responses, and a lack of clear rationales for scores. Primary reasons for their continued use include the richness and uniqueness of the material they produce, the applicability of some objective measures to that data, and the fact that in skilled hands the tests can provide remarkable insights into personality and psychopathology. Although judgments about instruments must ultimately be based on the test as a whole, and, above all, on the adequacy of interpretive procedures, insofar as those procedures are brought to bear on data of particular kinds, the strengths and weaknesses of the tests are determined in part by the projective task itself. Moreover, just as all investigatory methods involve tradeoffs, both their potentialities and limitations often bear an intimate relationship to one other.
Such a relationship exists with regard to issues of validity and the uniqueness of data. For example, on one common measure of validity, inferences made from symptom checklists or rating scales correlate more highly with psychiatrists’ diagnoses than those from most projective tests. Yet the very aspects of the test task that contribute most to those correlations, the fact that the former instruments often contain the same questions asked by a competent psychiatrist, limit their capacity to provide insights beyond those that may be obtained in an interview. In contrast, focusing as they do on modes of symbolization in a variety of at times unfamiliar media, ways in which individuals experience themselves and others, and fantasy and subjective experience, projective instruments produce data on aspects of human experience not readily accessible by other means. Such data may be of limited interest if the chief purpose of an assessment is to arrive at a DSM-IV diagnosis or titrate medication for a target symptom but of considerable help to a therapist looking for guidance in conducting an intensive psychotherapy process.
A similar relationship is present in considerations of reliability and the richness of data produced by projective tests. The degree of agreement about a score, as well as its implications, is, in part, a function of the number of possible solutions to a task. For example, it is easier to score arithmetic problems on an intelligence test, which have only one correct answer, than vocabulary or comprehension items, in which there are a number of acceptable answers and gradations in how close answers come to meeting criteria. Difficulties in scoring increase substantially with projective tests in which the very nature of the task is such that there is a multiplicity of responses. More important, reliability increases when the qualities being assessed can be determined from the response itself and require little consideration of its context. No knowledge of the life history of the subject or the situation in which an answer is given is needed to assess the solution to an arithmetic problem, apart from whether there are any circumstances that seriously interfere with the subject concentrating on the task at hand. The same is true in scoring aspects of projective tests such as the location or determinants of a Rorschach response. Thus, as Kline (1993) observes, some objective measures can be used with such instruments. Yet appreciating the meaning of other aspects of projective tests, notably those related to content such as a TAT story, may be greatly enhanced by knowledge of situational factors and the subject’s history. Such conditions obviously decrease agreement among psychologists who may differ in their knowledge, understanding, or weighting of such factors. Perhaps most significant, reliability is increased when responses have a limited range of possible meanings upon which consensus is easily established. Yet the most distinctive quality of art is the multiplicity of meanings condensed in a single work. For example, Ms. D.’s butterfly response “fits” the material with which she is working, yet also may well represent simultaneously a traumatic experience with which she is struggling, her sense of herself and her relationship to significant figures in her life, and her experience of the current test situation. In contrast to a good solution to an arithmetic problem, a work of art upon which all critics could agree rapidly, about which a variety of interpretations could not be offered, and indeed about which new interpretations cannot be continually arrived at would be a poor work indeed.
Finally, there is a relationship between complaints about psychometric problems with projective tests and their capacity in the hands of skilled clinicians to provide striking insights into an individual’s personality and pathology. As has been seen, some difficulties around issues of reliability and validity arise because of the effects of contextual factors on test responses, especially the ways in which self and other are construed in the test situation, and the richness of data, especially the multiplicity of meanings that can be condensed in artistic productions. Yet the very aspects of the projective task that depart from an ideal psychometric situation are similar structurally to those characteristic of an expressive psychotherapy process. There, too, the material produced is influenced by manifestations of transference and countertransference and treated as a text with multiple layers of meaning that relate to clients’ relationships with the therapist, issues in their current lives, and formative events in their histories. Interpretations of projective test material attributed either admiringly or disparagingly to clinical intuition do not arise chiefly from a mysterious process that depends on the special sensitivity of individual clinicians; rather they result from application of skills utilized by diagnosticians and therapists in treatment situations to material similar to that encountered in treatment situations in order to make inferences about behavior that is likely to occur in treatment situations. To be sure, this process of inference making has what Polanyi (1958, 1967) describes as a tacit dimension in the sense that the rules are often implicit in the actions of clinicians rather than explicitly articulated and depend upon skill and experience to be used effectively. Those rules also may differ from typical nomothetic procedures in that they involve qualitative judgments of which responses are especially significant and identifying patterns in projective test material. For example, markers for determining the importance of a response may relate to the emotion with which it is given, relationships to other responses, and departures from expected types of responses. However, since discussion of the logic of such analyses goes well beyond a consideration of the nature of the projective task, it is perhaps sufficient to note that the task is such that, when used effectively, such analyses can make significant contributions to personality assessment, but that also, because of the skill and experience required, they can lead to very poor assessment as well.
The Future of Projective Tests
The final question raised in the introduction was why, when so many questions surround projective tests, they should continue to have a claim on the interest of psychologists. Many who raise such questions have grounds for believing they should not, and, given the temper of the times, will not. Just as the acceptance of projective tests a half century ago was facilitated by a zeitgeist in which there was growing dissatisfaction with the prevailing empiricist orientations (Rabin, 1981; Sargent, 1945; Shneidman, 1965), today their continuing use is challenged by strong currents in contemporary society. Foremost among these antithetical forces are a powerful lobby within the academic arena that is hostile to diagnostic or therapeutic procedures that do not conform to narrowly defined empiricist criteria and a managed care environment in which there is limited support not only for personality assessment but also for any clinical activity other than brief, symptom-focused work.
Nonetheless, in spite of the many legitimate arguments that can be advanced against projective tests, in spite of current ideological battles, and in spite of changing economic conditions, there is one powerful reason for believing that projective tests will continue to play a prominent role in personality assessment: the nature of the task. As has been seen, whether consisting of forming images from inkblots, telling stories about a boy with a violin, or deciding which animal one’s mother most resembles, projective tests are not quaint exercises that are subjected to esoteric interpretations. At their core, they consist of the production and analysis of forms of artistic representation. As such, they focus ultimately on fundamental ways in which human beings throughout their history have given expression to thoughts and feelings of deepest concern to them. Thus, although specific projective tasks and, even more, ways in which they are analyzed will no doubt change considerably over time, insofar as psychology remains a discipline concerned with how the mind works, it is inconceivable that exploration of so basic a form of human endeavor will not continue to play a vital role among its methods.
REFERENCES
- Abt, L.E. (1950). A theory of projective psychology. In L.E. Abt & L. Bellak (Eds.), Projective psychology: Clinical approaches to the total personality (pp. 33–66). New York: Alfred A. Knopf.
- Allen, R.M. (1954). Continued longitudinal Rorschach study of a young child for years three to five. Journal of Genetic Psychology, 85, 135–149.
- Ames, L.B., Learned, J., Metraux, J., & Walker, R.N. (1952). Child Rorschach responses. New York: Paul B. Hoeber.
- Bell, J.E. (1948). Projective techniques. New York: Longmans.
- Bellak, L. (1950). On the problems of the concept of projection: A theory of apperceptive distortion. In L.E. Abt & L. Bellak (Eds.),
- Berg, M. (1986). Diagnostic use of the Rorschach with adolescents. In A.I. Rabin (Ed.), Projective techniques for adolescents and children (pp. 111–141). New York: Springer.
- Binet, A., & Henri, V. (1895–1896). La psychologie individuelle. Annuel Psychologie, 2, 411–465.
- Blum, G.S. (1949). A study of the psychoanalytic theory of psychosexual development. Genetic Psychology Monographs, 39, 3–99.
- Bruhn, A.R. (1990). Earliest childhood memories: Volume 1. New York: Praeger.
- Cassirer, E. (1944) An essay on man. New Haven, CT: Yale University Press.
- Cattell, R.B. (1951). Principles of design in “projective” or misperception tests of personality. In H.H. Anderson & G.I. Anderson (Eds.), An introduction to projective tests (pp. 55–98). New York: Prentice-Hall.
- Dearborn, G. (1898). A study of imagination. American Journal of Psychology, 9, 183–190.
- Ellenberger, H. (1954). The life and work of Hermann Rorschach. Bulletin of the Menninger Clinic, 18, 171–222.
- Exner, J.E. (1986). The Rorschach: A comprehensive system (2nd ed.). New York: Wiley.
- Frank, L.K. (1939). Projective methods for the study of personality. Journal of Psychology, 8, 389–413.
- Gardner, H. (1980). Artful scribbles: The significance of children’s drawings. New York: Basic Books.
- Gardner, H. (1982). Art, mind, and brain: A cognitive approach to creativity. New York: Basic Books.
- Gibson, J.J. (1956). The non-projective aspects of the Rorschach experiment: IV. The Rorschach blots considered as pictures. Journal of Social Psychology, 44, 203–206.
- Goodman, N. (1976). Languages of art. Indianapolis, IN: Hackett.
- Hansburg, H.R. (1986). The separation anxiety test. In A.I. Rabin (Ed.), Projective techniques for adolescents and children (pp. 85– 108). New York: Springer.
- Harris, D.B. (1963). Children’s drawings as measures of intellectual maturity. New York: Harcourt, Brace, & World.
- Holt, R.R. (1978). Methods in clinical psychology: Volume 1. Projective assessment. New York: Plenum.
- Hutt, M.L. (1980). The Michigan Picture Test—Revised. New York: Grune & Stratton.
- Jensen, A.R. (1980). Bias in mental testing. New York: Free Press.
- Kaplan, L.J. (1975). Testing nontestable children. Bulletin of the Menninger Clinic, 39, 420–435.
- Kirkpatrick, E.A. (1900). Individual tests of school children. Psychological Review, 7, 274–280.
- Kleiger, J. (1999). Disordered thinking and the Rorschach. Hillsdale, NJ: Analytic Press.
- Kline, P. (1993). The handbook of psychological testing. London: Routledge.
- Klopfer, B., Spiegelman, M., & Fox, J. (1956). The interpretation of children’s records. In B. Klopfer (Ed.), Developments in Rorschach technique, Volume 2 (pp. 22–44). New York: Harcourt, Brace, & World.
- Leichtman, M. (1995). Behavioral observations. In J.N. Butcher (Ed.), Clinical personality assessment: Practical approaches (pp. 251–266). New York: Oxford University Press.
- Leichtman, M. (1996a). The nature of the Rorschach task. Journal of Personality Assessment, 67, 478–493.
- Leichtman, M. (1996b). The Rorschach: A developmental perspective. Hillsdale, NJ: Analytic Press.
- Leichtman, M., & Nathan, S. (1983). A clinical approach to the psychological testing of borderline children. In K. Robson (Ed.), The borderline child: Approaches to etiology, diagnosis, and treatment (pp. 121–170). New York: McGraw-Hill.
- Lerner, P. (1991). Psychoanalytic theory and the Rorschach. Hillsdale, NJ: Analytic Press.
- Lerner, P. (1998). Psychoanalytic perspectives in the Rorschach. Hillsdale, NJ: Analytic Press.
- Lindzey, G. (1961). Projective techniques and cross cultural research. New York: Appleton-Century-Crofts.
- Masling, J.M. (1960). Interpersonal and situational influence in projective testing. Psychological Bulletin, 57, 65–85.
- Masling, J.M. (1966). Role-related behavior of the subject and psychologist and its effects upon psychological data. In D. Levine (Ed.), Symposium on motivation (pp. 67–104). Lincoln: University of Nebraska.
- Mayman, M. (1968). Early memories and character structure. Journal of Projective Techniques, 32, 303–316.
- Morgan, C., & Murray, H.A. (1935). A method for investigating fantasies: The Thematic Apperception Test. Archives of Neurology and Psychiatry, 34, 289–306.
- Murray, H.A. (1938). Explorations in personality. New York: Oxford University Press.
- Murstein, B.I., & Pryer, R.S. (1959). The concept of projection: A review. Psychological Bulletin, 56, 353–374.
- Olson, D., & Campbell, R. (1993). Constructing representations. In C. Pratt & A.F. Garton (Eds.), Systems of representation in children (pp. 11–26). New York: Wiley.
- Parsons, C.J. (1917). Children’s interpretations of inkblots. British Journal of Psychology, 9, 74–92.
- Perner, J. (1991). Understanding the representational mind. Cambridge, MA: MIT Press/Bradford Books.
- Piotrowski, Z.A. (1950). A Rorschach compendium (Rev. ed.). Psychiatric Quarterly, 24, 545–596.
- Piotrowski, Z.A. (1981, May). The Piotrowski system. Lecture presented to the Union Country Association of School Psychologists, Clark, NJ.
- Polanyi, M. (1958). Personal knowledge: Towards a post-critical philosophy. Chicago: University of Chicago Press.
- Polanyi, M. (1967). The tacit dimension. Garden City, NY: Anchor Books.
- Pratt, C., & Garton, A.F. (1993). Systems of representation in children. In C. Pratt & A.F. Garton (Eds.), Systems of representation in children (pp. 1–9). New York: Wiley.
- Pyle, W.H. (1915). A psychological study of bright and dull pupils. Journal of Educational Psychology, 6, 151–156.
- Rabin, A.I. (1981). Projective methods: A historical introduction. In A.I. Rabin (Ed.), Assessment with projective techniques: A concise introduction (pp. 1–22). New York: Springer.
- Rapaport, D., Gill, M., & Schafer, R. (1945). Diagnostic psychological testing: The theory, statistical evaluation, and diagnostic application of a battery of tests. Chicago: Year Book. (Revised Ed., 1968, R.R. Holt, Ed.).
- Rorschach, H. (1921). Psychodiagnostik. Bern: Ernest Bircher. (Translation Psychodiagnostics, 6th ed. New York: Grune & Stratton, 1964.)
- Rosenzweig, M. (1960). The Rosenzweig Picture-Frustration Study, a children’s form. In A.I. Rabin & M.R. Haworth (Eds.), Projective tests with children (pp. 149–176). New York: Grune & Stratton.
- Sargent, H. (1945). Projective methods: Their origins, theory, and application in personality research. Psychological Bulletin, 42, 257–293.
- Sattler, J.M. (1988). Assessment of children’s intelligence and special abilities (3rd ed.). San Diego, CA: Jerome M. Sattler.
- Schachtel, E. (1966). Experiential foundations of Rorschach’s test. New York: Basic Books.
- Schafer, R. (1954). Psychoanalytic interpretation in Rorschach testing. New York: International Universities Press.
- Schafer, R. (1956). Transference in the patient’s reaction to the tester. Journal of Projective Techniques, 20, 26–32.
- Schafer, R. (1967). Projective testing and psychoanalysis. New York: International Universities Press.
- Schlesinger, H. (1973). Interaction of dynamic and reality factors in the diagnostic testing interview. Bulletin of the Menninger Clinic, 37, 495–517.
- Shneidman, E.S. (1965). Projective techniques. In B.J. Wolman (Ed.), Handbook of clinical psychology (pp. 498–521). New York: McGraw-Hill.
- Solomon, I.L., & Starr, B.D. (1968). School Apperception Method: SAM. New York: Springer.
- Sugarman, A. (1981). The diagnostic use of countertransference reactions in psychological testing. Bulletin of the Menninger Clinic, 45, 473–490.
- Terman, L., & Merrill, M. (1960). Stanford-Binet Intelligence Scale. Boston: Houghton Mifflin.
- Wechsler, D. (1991). Wechsler Intelligence Scale for Children third edition: Manual. San Antonio, TX: Psychological Corporation.
- Weiner, I. (1986). Assessing children and adolescents with the Rorschach. In H.M. Knoff (Ed.), The assessment of child and adolescent personality (pp. 141–171). New York: Guilford Press.
- Werner, H., & Kaplan, B. (1963). Symbol formation. New York: Wiley.
- White, R.W. (1944). Interpretation of imaginative productions. In J. McV. Hunt (Ed.), Personality and behavior disorders (pp. 214– 251). New York: Ronald Press.
- Zubin, J., Eron, L.D., & Schumer, F. (1965). An experimental approach to projective techniques. New York: Wiley.
CHAPTER 25 The Reliability and Validity of the Rorschach and Thematic Apperception Test (TAT) Compared to Other Psychological and Medical Procedures: An Analysis of Systematically Gathered Evidence
GREGORY J. MEYER
META-ANALYSES OF INTERRATER RELIABILITY IN PSYCHOLOGY AND MEDICINE 316 Overview of Procedures 316 Broad Search for Existing Meta-Analyses or Systematic Reviews 317 Focused Searches for Literature Reviews 321 New Meta-Analytic Studies of Interrater Reliability 322 Summary of Meta-Analytic Studies of Interrater Reliability 324
Over the last 6 years, a series of strident criticisms have been directed at the Rorschach (e.g., Garb, 1999; Grove & Barden, 1999; Wood, Lilienfeld, Garb, & Nezworski, 2000; Wood, Nezworski, Garb, & Lilienfeld, 2001; Wood, Nezworski, & Stejskal, 1996) and countered by conceptual and empirical rebuttals (e.g., Acklin, 1999; Exner, 1996, 2001; Garfield, 2000; Hilsenroth, Fowler, Padawer, & Handler, 1997; Meyer, 2001a, 2002; Meyer et al., 2002; Ritzler, Erard, & Pettigrew, 2002; Weiner, 2000). Perhaps most significantly, two special sections in the journal Psychological Assessment brought together representatives from these opposing perspectives to debate the Rorschach’s evidentiary foundation in a structured and sequential format that allowed for a full consideration of its strengths and limitations (Meyer, 1999, 2001b).
In a legal context, Grove and Barden (1999) argued that because the Rorschach has the most extensive body of reMETA-ANALYSES OF TEST-RETEST RELIABILITY 325 META-ANALYSES OF TEST VALIDITY 328 SUMMARY CONCLUSIONS 328 APPENDIX: CITATIONS CONTRIBUTING DATA TO THE LARGER META-ANALYSES OF INTERRATER RELIABILITY CONDUCTED FOR THIS CHAPTER 331 NOTES 333 REFERENCES 333
search supporting its psychometric properties, any critical deficiencies that could be identified for it should also generalize to the other less studied performance tasks used to assess personality, such as the Thematic Apperception Test (TAT), sentence completion tests (SCTs), or figure drawings. And indeed, substantial criticisms have recently been leveled against all of these procedures (Lilienfeld, Wood, & Garb, 2000). Importantly, these criticisms extended beyond the professional journals to capture public attention. Lilienfeld et al.’s disparaging review of these instruments was discussed in a prominent New York Times story (Goode, 2001) and a shorter, repackaged version of the review appeared in the widely circulated popular magazine Scientific American (Lilienfeld, Wood, & Garb, 2001).
With this background setting the stage, my central purpose in this chapter is to provide a broad overview of the psychometric evidence for performance-based personality tests, with a primary focus on the Rorschach and TAT. However, any review that focuses exclusively on the reliability and validity evidence for these instruments (e.g., Lilienfeld et al., 2000) encounters a serious limitation. Once the evidence is in hand, one must determine whether it provides reasonable support for a test, evidence of salient deficiencies, or some combi-
Acknowledgments: A grant from the Society for Personality Assessment supported the preparation of this chapter and the new research it reports, including the complete recoding and reexamination of Parker, Hanson, and Hunsley’s (1988) meta-analyses on the convergent validity of the WAIS, MMPI, and Rorschach initially reported in Meyer and Archer (2001).
nation, such that the test may be considered reliable and valid for some purposes but not others. Stated differently, the psychometric evidence must be processed and linked to other knowledge in order to be interpreted in a sensible fashion. However, processing and interpreting a complex body of information provides many opportunities for the cognitive biases that afflict all humans to exert their influence (Arkes, 1981; Borum, Otto, & Golding, 1993; Garb, 1998; Hammond, 1996; Spengler, Strohmer, Dixon, & Shivy, 1995).
For instance, does an intraclass correlation of .70 indicate that the interrater reliability for test scoring is good or poor? Does a 5-year test-retest correlation of .50 provide favorable or unfavorable evidence regarding the traitlike stability of a test scale? Does a correlation of .30 between a scale and a relevant criterion provide reasonable evidence for or against the construct validity of a test? When answering each of these questions, the evidence is open to interpretation. And preexisting beliefs, schemas, and affective reactions will shape how one makes sense of the data. Thus, if the coefficients listed previously had been found for the Rorschach, psychologists with a generally unfavorable stance toward this test may be prone to view all of the findings as deficient and as indications the Rorschach should not be used in applied clinical practice. In contrast, psychologists who have a generally favorable preexisting stance toward the test may be prone to view all three examples as indicating reasonable, positive evidence that supports Rorschach reliability and validity. Both sides could find legitimate reasons to argue their positions and they likely would never achieve a resolution, particularly if one or both sides did not consider the magnitude of the reliability and validity coefficients that are typically obtained for other kinds of instruments.
A number of authors have suggested strategies to help minimize or rectify the cognitive biases that affect judgments made under complex or ambiguous circumstances (Arkes, 1981; Borum et al., 1993; Spengler et al., 1995). Invariably, these strategies include some method for listing and systematically attending to information, particularly information that may disconfirm an initial impression or a faulty memory. In the present context, this general de-biasing strategy will be implemented in two ways.
First, data will be drawn from systematically gathered meta-analytic evidence. By statistically summarizing a body of literature, meta-analyses provide a more accurate understanding of existing knowledge than the study-by-study examination of findings found in the traditional narrative review (e.g., Lilienfeld et al., 2000). The value of meta-analysis as a scientific de-biasing procedure was pointedly stated by Chalmers and Lau (1994) when contrasting meta-analysis with conventional reviews in medicine:
Too often, authors of traditional review articles decide what they would like to establish as the truth either before starting the review process or after reading a few persuasive articles. Then they proceed to defend their conclusions by citing all the evidence they can find. The opportunity for a biased presentation is enormous, and its readers are vulnerable because they have no opportunity to examine the possibilities of biases in the review. (cited in Hunt, 1997, p. 7)
Indeed, meta-analyses have regularly clarified the scientific foundation behind controversial areas of research and have often overturned the accepted wisdom derived from narrative reviews (see Hunt, 1997, for compelling examples).
Second, the psychometric data presented in this chapter will not be limited to tests like the Rorschach and TAT, which evoke strong reactions from many psychologists. Rather, reliability and validity evidence for these instruments will be presented alongside evidence for alternative measures in psychology, psychiatry, and medicine. Doing so will allow readers to compare and weigh the evidence from a relatively broad survey of findings in applied health care. If tests like the Rorschach or TAT have notable psychometric deficiencies, these flaws should be quite obvious when relevant data are compared across assessment procedures.
Space limitations combined with a need to document the steps for systematically sampling the literature result in a chapter that is long on detail and relatively short on commentary. The overview begins with reliability and then examines validity. Reliability is considered in two categories, interrater agreement and retest stability. Interrater reliability indicates how well two people agree on the phenomenon they are observing. This form of reliability is critical to many human endeavors, including the clinical practice of psychology, psychiatry, and medicine. Because it is so important, interrater agreement has been studied frequently and a substantial literature exists from which to systematically cull data. Testretest reliability documents the extent to which a measured construct has relatively constant, traitlike characteristics. This type of reliability is regularly investigated in psychology but has received less attention in medicine. Thus, the review presented here will be limited in scope.
META-ANALYSES OF INTERRATER RELIABILITY IN PSYCHOLOGY AND MEDICINE
Overview of Procedures
To obtain systematically organized data on interrater reliability, several strategies were used. These included (1) a broad search for existing data summaries, (2) narrow searches for literature reviews that identified interrater studies and allowed meta-analytic results to be computed, and (3) new meta-analyses derived from a thorough search of relevant literature.
For a study to contribute data, reliability had to be reported as a correlation, intraclass correlation (ICC), or kappa coefficient (j). ICCs and j coefficients correct observed agreement for chance agreement and are often lower than Pearson correlations. Common interpretive guidelines for j and the ICC are as follows: Values less than .40 indicate poor agreement, values between .40 and .59 indicate fair agreement, values between .60 and .74 indicate good agreement, and values greater than .74 indicate excellent agreement (Cicchetti, 1994).
Interrater reliability studies vary along several dimensions, including the number of objects rated (n), the number of judges (k) that examine and rate each object, and the number of qualities that are rated (q). Because of these differences, there are several weights that can be applied to samples when computing meta-analytic summary statistics. Meta-analyses traditionally ignore the number of qualities considered in a sample (e.g., in treatment outcome research, the results from multiple outcomes are simply averaged within a sample), so this variable was not considered further. The possible weights that remain include: n(k), which indicates the total number of independent judgments in a sample; n(k(k ! 1)/2), which indicates the total number of paired rater judgments in a sample; and n(k ! 1), which indicates the maximum number of independently paired judgments in a sample.1 Because n(k) does not reduce to n in a traditional two-judge design and because n(k(k ! 1)/2) counts nonindependent judgments and increases quadratically as more judges are used, n(k ! 1) was used to weigh sample results whenever new computations were undertaken. This weight reduces to n in a twojudge design, gives appropriate added emphasis to multirater studies, provides a summary value that can be meaningfully interpreted, and ensures that excessively large weights are not assigned to designs containing multiple, nonindependent judgments. For the studies reported here, the different weights almost always produced similar results. I note the two instances when alternative weighing led to results that differed by more than .03 from the value obtained using n(k ! 1).
Some studies report reliability coefficients after they have been corrected according to the Spearman-Brown formula, which estimates the reliability for a multirater composite (e.g., for an average score computed across three raters). Because these adjusted coefficients are higher than traditional findings (i.e., the association between one rater and another), whenever Spearman-Brown estimates were reported, the findings were back-transformed to indicate reliability for a single rater using Table 3.10 in Rosenthal (1991).
Table 25.1 presents a summary of the interrater reliability research to be described more fully later. For each construct, the table indicates how many independent pairs of observations produced the findings, as well as the average reliability coefficient. Reliability coefficients were computed separately for scales and items. Items are single units of observation or single judgments, while scales are derived from the numerical aggregation of item-level judgments. Because aggregation allows random measurement errors associated with the lowerlevel items to cancel out, scales should be more reliable than items. Reliability coefficients were also computed separately for correlations and for chance-corrected coefficients (i.e., j/ICC).
The findings in Table 25.1 are roughly organized by magnitude. This ordering attempts to take into account itemscale differences and differences between correlations and chance-corrected coefficients. However, because the ordering is imprecise and because some samples are small, minor differences in rankings should be ignored.
Broad Search for Existing Meta-Analyses or Systematic Reviews
To identify existing data summaries, I searched PsycINFO and PubMed in August 2001 for meta-analyses that had examined interrater reliability. Using the overly inclusive terms reliability or agreement combined with meta-analy*, 304 nonduplicate, English-language articles were identified. Subsequently, the search on PubMed was expanded by combining the medical subject heading (MeSH) categories meta-analysis or review literature or the text phrase systematic-review with the MeSH terms reproducibility of results or observer variation. After excluding articles without abstracts, the new search identified 214 studies, 189 of which did not overlap with the prior search. After reviewing these 493 abstracts and deleting those that clearly were not designed to summarize data on interrater reliability, 63 studies remained. To these I added two relevant reviews that did not appear in the searches (Etchells, Bell, & Robb, 1997; Gosling, 2001). All 65 articles were obtained and 25 contained either summary data on interrater reliability or a complete list of studies that provided relevant results. For the latter, all of the original citations were obtained and their findings were aggregated. A brief description of each review follows, starting with those addressing psychological topics.
Two nonoverlapping meta-analyses (Achenbach, Mc-Conaughy, & Howell, 1987; Duhig, Renk, Epstein, & Phares, 2000) examined the reliability of ratings made on child or
318 Reliability and Validity
TABLE 25.1 Meta-Analyses of Interrater Reliability in the Psychological and Medical Literature
| Number of independent Target reliability construct pairs of judgments Scale Item Scale 1. Bladder Volume by Real-Time Ultrasound 40 .95 320 2. Count of Decayed, Filled, or Missing Teeth (or Surfaces) in Early Childhood 113 .97 237 3. Rorschach Oral Dependence Scale Scoring 934 .91 40 .91 6,430 4. Measured Size of the Spinal Canal and Spinal Cord on MRI, CT, or X-Ray 200 .90 86 .88 5. Scoring the Rorschach Comprehensive Systema : Summary scores 219 .90 565 .91 Response segments 11,518 Scores for each response 11,572 6. Neuropsychologists’ Test-Based Judgments of Cognitive Impairment 901 7. Hamilton Depression Rating Scale Scoring From Joint Interviewsb 1,773 .93 334 .68 2,074 .80 161 8. Hamilton Anxiety Rating Scale Scoring From Joint Interviewsb 512 .91 240 .87 214 9. Level of Drug Sedation by ICU Physicians or Nurses 327 .91 789 .84 165 10. Functional Independence Measure 1,365 .91 1,345 11. TAT Personal Problem-Solving Scale Scoring 282 .86 103 .83 12. Borderline Personality Disorder: Diagnosis 402 .82 Specific symptoms 198 13. Signs and Symptoms of Temporomandibular Disorder 192 .86 562 14. Hamilton Anxiety Rating Scale Scoring From Separate Interviews 60 .65 208 .79 208 15. Axis I Psychiatric Diagnosis by Semi-Structured SCID in Joint Interviews 216 .75 16. Axis II Psychiatric Diagnosis by Semi-Structured Joint Interviews 740 .73 17. Hamilton Depression Rating Scale Scoring From Separate Interviews 649 .88 367 .55 363 .72 230 18. TAT Social Cognition and Object Relations Scale Scoring 653 .86 281 .72 19. Rorschach Prognostic Rating Scale Scoring 472 .84 |
||
|---|---|---|
| Item | ||
| .92 | ||
| .79 | ||
| .84 | ||
| .86 | ||
| .83 | ||
| .80 | ||
| .77 | ||
| .72 | ||
| .71 | ||
| .62 | ||
| .64 | ||
| .56 | ||
| .58 | ||
| .46 | ||
| 713 .80 |
20. TAT Defense Mechanism Manual Scoring | |
| 30 .79 |
||
| 21. Therapist or Observer Ratings of Therapeutic Alliance in Treatment (S ” 31) .78 |
||
| 22. Type A Behavior Pattern by Structured Interview (S ” 3) .74 |
||
| 23. Job Selection Interview Ratings 12,549 .70 |
||
| 24. Personality or Temperament of Mammals 151 .71 |
||
| 637 .49 |
||
| 25. Editors’ Ratings of the Quality of Manuscript Reviews or Reviewers 113 .66 |
.54c | |
| 3,608 26. Visual Analysis of Plotted Behavior Change in Single-Case Research 410 .61 |
||
| 867 | .55 | |
| 27. Presence of Clubbing in Fingers or Toes 630 |
.52d | |
| 28. Stroke Classification by Neurologists 1,362 |
.51 | |
| 29. Axis I Psychiatric Diagnosis by Semi-Structured SCID in Separate Interviews 693 .56 |
TABLE 25.1 (Continued)
| n(k ! 1) “ Number of independent |
r | j/ICC | |||
|---|---|---|---|---|---|
| Target reliability construct | pairs of judgments | Scale | Item | Scale | Item |
| 30. Axis II Psychiatric Diagnosis by Semi-Structured Separate Interviews | 358 | .52 | |||
| 31. Child or Adolescent Problems: | |||||
| Teacher ratings | 2,100 | .64 | |||
| Parent ratings | 4,666 | .59 | |||
| Externalizing problems | 7,710 | .60 | |||
| Internalizing problems | 5,178 | .54 | |||
| Direct observers | 231 | .57 | |||
| Clinicians | 729 | .54 | |||
| 32. Job Performance Ratings by Supervisors | 1,603 | .57 | |||
| 10,119 | .48 | ||||
| 33. Self and Partner Ratings of Conflict: | |||||
| Men’s aggression | 616 | .55 | |||
| Women’s aggression | 616 | .51 | |||
| 34. Determination of Systolic Heart Murmur by Cardiologists | 500 | .45 | |||
| 35. Abnormalities on Clinical Breast Examination by Surgeons or Nurses | 1,720 | .42 | |||
| 36. Mean Quality Scores From Two Grant Panels: | |||||
| Dimensional ratings | 1,290 | .41 | |||
| 1,177 | .46 | ||||
| Dichotomous decision | 398 | .39 | |||
| 37. Job Performance Ratings by Peers | 1,215 | .43 | |||
| 6,049 | .37 | ||||
| 38. Number of Dimensions to Extract From a Correlation Matrix by Scree Plots | 2,300 | .35 | |||
| 39. Medical Quality of Care as Determined by Physician Peers | 9,841 | .31 | |||
| 40. Definitions of Invasive Fungal Infection in the Clinical Research Literature | 21,653 | .25 | |||
| 41. Job Performance Ratings by Subordinates | 533 | .29 | |||
| 4,500 | .31 | ||||
| 42. Research Quality by Peer Reviewers: | |||||
| Dimensional ratings | 6,129 | .30 | |||
| 24,939 | .24 | ||||
| Dichotomous decisions | 4,807 | .21 |
Note. See text for complete description of sources contributing data to this table. CT ” computed tomography, Dx ” diagnosis, ICC ” intraclass correlation, ICU ” intensive care unit, j ” kappa, MRI ” magnetic resonance imaging, r ” correlation, S ” number of studies contributing data, SCID ” Structured Clinical Interview for the DSM (Diagnostic and Statistical Manual of Mental Disorders), and TAT ” Thematic Apperception Test.
a Results reported here differ slightly from those in Meyer et al. (2002) because Meyer et al. used n(k(k ! 1)/2) to weigh samples. For response segments, the number of independent pairs of judgments is the average across segments rather than the maximum per segment (17,540) or the total across all samples (18,040).
b This category included ratings of videotaped interviews and instances when the patient’s report fully determined both sets of ratings (e.g., the patient completed the scale in writing and then was asked the same questions in a highly structured oral format; the patient was given a highly structured personal interview and then immediately thereafter was asked the same highly structured questions via the telephone).
c For agreement among editors on the quality of peer reviewers, results varied noticeably depending on the weighting scheme selected and thus should be considered tentative. Reliability was .58 when weighing by the total number of independent ratings and it was .48 when weighing by the total number of objects judged by all possible combinations of rater pairs.
d One study produced outlier results (j ” .90) relative to the others (j range from .36 to .45). When weighing by the total number of independent ratings j remained at .52, but when weighing by the total number of objects judged by all possible rater pair combinations j was .46.
adolescent behavioral and emotional problems (Table 25.1, Entry 31). Duhig et al. only examined interparent agreement and their findings were combined with those reported by Achenbach et al. Using the Conflict Tactics Scales, Archer (1999; Table 25.1, Entry 33) examined the extent to which relationship partners agreed on each other’s aggressiveness. Conway, Jako, and Goodman (1995; Table 25.1, Entry 23) examined agreement among interviewers conducting job selection interviews.
The search identified three meta-analyses on the interrater reliability of job performance ratings (Conway & Huffcutt, 1997; Salgado & Moscoso, 1996; Viswesvaran, Ones, & Schmidt, 1996), as well as one large-scale study that combined data on this topic from 79 settings (Rothstein, 1990). Because Conway and Huffcutt provided the most differentiated analysis of rater types (i.e., supervisors, peers, and subordinates; see Table 25.1, Entries 32, 37, and 41) and also presented results for summary scales and for items, their findings were used.
Garb and Schramke (1996; Table 25.1, Entry 6) examined judgments about cognitive impairment derived from neuropsychological test findings. Results were computed from all the interrater data in their review. Gosling (2001; Table 25.1, Entry 24) examined temperament in mammals. He evaluated the extent to which researchers or others familiar with the target animals could agree on their personality traits. Gosling’s results were retabulated to allow ratings made on items to be separated from those made using scales. Because the within and between subject correlations (i.e., Q- and R-type correlations) he reported were similar, results from both designs were combined. Grueneich (1992; Table 25.1, Entry 12) examined the reliability of clinicians for diagnosing borderline personality disorder. The original studies he cited were checked to determine the Ns used in the reliability analyses. Martin, Garske, and Davis (2000; Table 25.1, Entry 21) examined ratings on the extent to which patients had a strong and positive alliance with their therapists. The results reported here excluded one study that used patients as the raters. A metaanalysis on scoring the Rorschach Comprehensive System was identified in the literature search (Meyer, 1997). However, the results in Table 25.1 are from a more recent metaanalysis on this topic (Meyer et al., 2002; Table 25.1, Entry 5).
Ottenbacher (1993) examined the interpretation of visually plotted behavior change, as used in behavior therapy or single-case research designs. He reported an average interrater reliability coefficient of .58 but his results included intrarater reliability and percent agreement coefficients. Consequently, the journal studies in his meta-analysis were obtained and intrarater or percent agreement findings were omitted (Table 25.1, Entry 26). Intraclass correlations were used in nine samples (Gibson & Ottenbacher, 1988; Harbst, Ottenbacher, & Harris, 1991; Ottenbacher, 1986; Ottenbacher & Cusik, 1991), while correlations were used in two additional samples (DeProspero & Cohen, 1979; Park, Marascuilo, & Gaylord-Ross, 1990).
Ottenbacher, Hsu, Granger, and Fiedler (1996; Table 25.1, Entry 10) examined the Functional Independence Measure, which is an index of basic self-care skills. Studies in their Table 2 were obtained to determine N and to differentiate item- and scale-level reliability. One study was excluded because it did not report the reliability N. Finally, Yarnold and Mueser (1989; Table 25.1, Entry 22) conducted a small metaanalysis of the Type A behavior pattern as determined by the Structured Interview, which is an instrument developed for this purpose.
With respect to medically related studies, Barton, Harris, and Fletcher (1999; Table 25.1, Entry 35) examined the extent to which surgeons and/or nurses agreed on the presence of breast abnormalities based on a clinical examination. Results were computed from all the data in their review and one primary study was obtained to determine N. De Jonghe et al. (2000; Table 25.1, Entry 9) examined ratings from intensive care physicians or nurses on the extent to which patients were sedated from medications designed for this purpose (e.g., to facilitate time on a ventilator). De Kanter et al. (1993) conducted a meta-analysis on the prevalence of temporomandibular disorder symptoms, not the reliability of assessing those symptoms. However, they provided citations for all the interrater reliability analyses that had been conducted in the context of prevalence research. Those six studies were obtained. Two presented intrarater reliability coefficients, one presented no specific reliability results, and two others presented statistics that could not be cumulated for the current review (i.e., percent agreement; mean differences). Data from the remaining study (Dworkin, LeResche, DeRouen, & Von Korff, 1990) were combined with the new data reported by De Kanter et al. (Table 25.1, Entry 13).
The original studies in D’Olhaberriague, Litvan, Mitsias, and Mansbach’s (1996; Table 25.1, Entry 28) systematic review on stroke classification were obtained to determine the number of patients and neurologists participating in each sample. An independent subsample of stroke classifications in Gross et al. (1986) was initially overlooked by D’Olhaberriague et al. but was included here. Etchells et al. (1997; Table 25.1, Entry 34) examined the extent to which cardiologists agreed on the presence of a systolic heart murmur. The authors reported the N for each study in their review, but not the number of cardiologist examiners. Because the primary sources were obscure, it was assumed that each study used two cardiologists. Goldman (1994; Table 25.1, Entry 39) examined the extent to which physician reviewers agreed on the quality of medical care received by patients.
Ismail and Sohn’s (1999) systematic review identified 20 reliability studies on early childhood dental caries. These studies examined the extent to which dentists or hygienists agreed on the number of teeth or tooth surfaces that were decayed, had fillings, or were missing (Table 25.1, Entry 2). Two of their 20 studies contained intrarater reliability, 7 presented statistics that could not be cumulated for the current review, and 3 did not report N for the reliability analysis. A final excluded study computed reliability for student practice examinations that were all conducted under the direct supervision of a single trainer. Of the remaining seven studies, scale-level data were provided by Yagot, Nazhat, and Kuder (1990), while item-level classifications were provided by Dini, Holt, and Bedi (1988); Jones, Schlife, and Phipps (1992); Katz, Ripa, and Petersen (1992; only results for the dentists and hygienists); Marino and Onetto (1995; the number of examiners was not specified, so two was assumed; reliability was reported to be ! .90, so the value .91 was used); O’Sullivan and Tinanoff (1996); and Paunio, Rautava, Helenius, Alanen, and Sillanpa¨a¨ (1993). The Ns for this metaanalysis refer to the number of children included in the reliability studies, not the number of teeth or tooth surfaces examined.
Myers and Farquhar (2001; Table 25.1, Entry 27) reviewed the extent to which physicians agreed that patients had clubbing in their fingers or toes (enlargement at the tips) based on a visual clinical examination. Although one study in their review produced outlier results (j ” .90) relative to the others (j range from .36–.45), it was retained in the summary data. Nwosu, Khan, Chien, and Honest (1998) did not conduct a meta-analysis of reliability for measuring bladder volume by ultrasound, but they indicated the three citations in the literature that provided available data (Table 25.1, Entry 1). One study (Ramsay, Mathers, Hood, & Torbet, 1991) reported an imprecise Spearman correlation that had been rounded to one decimal place. However, they also presented a figure of raw data for their reliability analysis, so both a Pearson correlation and ICC were computed from their findings.
In a review examining the physical measurement of spinal canal and spinal cord size from MRI, CT, or X-ray scans, Rao and Fehlings (1999) found seven reliability studies in the literature and provided new data from their own study (Fehlings et al., 1999). Of the studies identified in their literature search, one reported intrarater reliability, three presented mean differences, and one provided findings for just 2 of the 20 variables examined. Thus, summary results (Table 25.1, Entry 4) came from Fehlings et al. (1999), Matsuura et al. (1989), and Okada, Ikata, and Katoh (1994).
Finally, Ascioglu, de Pauw, Donnelly, and Collette (2001; Table 25.1, Entry 40) used a novel approach to assess interrater agreement. Rather than reviewing the extent to which clinicians agreed a patient should be diagnosed with an invasive fungal infection, they examined the extent to which the definitions of invasive fungal infection in the research literature agreed with each other. Specifically, they found 60 studies that defined infection from the mold Aspergillus. They then classified 367 patients according to each definition to determine “how the same case would be evaluated if the patient had been entered into these different studies on the basis of the same diagnostic information” (Ascioglu et al., p. 36). Thus, the reliability coefficient indicates the extent to which findings in the research literature are based on the same definition of pathology.
Although the studies described in this section examine a wide range of phenomena, a number of notable holes remain in the evidence base. In particular, just one review addressed the Rorschach and none addressed the TAT. In addition, although one study examined borderline personality disorder, no summary evidence was available on the general reliability of assigning psychiatric diagnoses, which are probably the most frequent determinations made in psychology and psychiatry. Similarly, no evidence was available on commonly used psychiatric rating scales, such as the Hamilton Depression Rating Scale (HDRS) or Hamilton Anxiety Rating Scale (HARS). Finally, virtually all of the reviews addressed clinical issues and applications. With the exception of Gosling’s (2001) overview of mammal personality traits, no studies addressed the reliability of determinations that are more commonly or uniquely made as part of academic enterprises, such as the peer review of manuscripts and grants for scientific quality or the determination of how many factors should be extracted from a correlation matrix. To fill in these gaps, I conducted focused searches for existing literature reviews that identified reliability studies and completed several new searches for primary studies.
Focused Searches for Literature Reviews
To obtain data on the reliability of contemporary psychiatric diagnoses according to the Diagnostic and Statistical Manual of Mental Disorders (DSM; American Psychiatric Association, 1994), I searched for existing reviews of this literature. For DSM Axis I disorders, PubMed and PsycINFO were searched by combining the term review with the terms DSM, Diagnostic-and-Statistical, Axis-I, SCID, Structured-Clinical-Interview, Semi-Structured, or Structured-Interview and the terms reliability, agreement, interrater, or inter-rater. Non-English-language articles were excluded from PsycINFO. After combining 305 PubMed citations with 143 PsycINFO citations and deleting duplicates, 394 citations remained. Abstracts were reviewed and relevant articles were obtained. Several reviews identified in the search addressed interrater reliability for narrow diagnostic constructs (e.g., Steinberg, 2000; Szatmari, 2000; Weathers, Keane, & Davidson, 2001). Because it would be most valuable to have data organized across the wide range of conditions diagnosed by the DSM, these studies were not used. Instead, the data summarized here came from the studies included in Segal, Hersen, and Van Hasselt’s (1994) review of reliability for the Structured Clinical Interview for DSM-III-R (SCID). Original studies were obtained to determine the number of raters in each sample. In the process, it was discovered that one study (Stukenberg, Dura, & Kielcolt-Glaser, 1990) did not report reliability for any specific diagnoses but rather just for the presence or absence of any DSM disorder. This finding was excluded. Summary results were computed for both joint interview designs (Table 25.1, Entry 15) and for two independently conducted interviews (Table 25.1, Entry 29).
To find reviews covering the reliability of DSM Axis II personality disorders, PubMed and PsycINFO were searched by combining the term review with the terms personalitydisorder or Axis-II and the terms reliability, agreement, interrater, or inter-rater. After deleting duplicates, 101 citations remained. These abstracts and two recent special sections in the Journal of Personality Disorders (Livesley, 2000a, 2000b) were examined for relevant review articles.
Two reviews were found that summarized reliability across Axis II diagnoses. Segal et al. (1994) focused exclusively on the SCID, while Zimmerman (1994) cast a broader net and examined data derived from all the semistructured interviews in use for this purpose. Because Zimmerman’s overview suggested there was little difference in the reliability of interview schedules, his results were tabulated here. Zimmerman reported unweighted averages across studies for each Axis II diagnosis (his Table 5). To be consistent with the other findings summarized here, overall reliability was recomputed by averaging results within a study and then weighing by sample size. Zimmerman also provided preliminary data from an unpublished sample of Loranger’s. This information was supplemented with the complete findings described in the final published report (Loranger et al., 1994). As with Axis I disorders, summary results were computed for joint interviews (Table 25.1, Entry 16) and for independent interviews conducted over a short interval (Table 25.1, Entry 30).
New Meta-Analytic Studies of Interrater Reliability
By searching the literature for narrative reviews it was possible to generate meta-analytic summaries for the reliability of Axis I and Axis II diagnoses obtained through commonly used semistructured interviews. Although valuable, to further the knowledge base concerning interrater agreement a series of new meta-analyses was undertaken addressing psychological tests (i.e., Rorschach, TAT, and Hamilton scales) and traditional academic pursuits (i.e., the ubiquitous peer-review process and the interpretation of scree plots).
Rorschach Scales
Two new meta-analyses were conducted to summarize interrater reliability of Rorschach scoring. One examined the Rorschach Oral Dependency (ROD) Scale and the other Klopfer’s Rorschach Prognostic Rating Scale (RPRS). The ROD was selected because it appears to be the most commonly studied Rorschach scale in the literature (see Bornstein, 1996, for an overview). The RPRS was selected because its predictive validity was examined in two recent meta-analyses (Meyer, 2000; Meyer & Handler, 1997).
To identify ROD interrater reliability studies, Bornstein’s (1996) review was consulted and three PsycINFO searches were undertaken. After the first two were completed, Robert Bornstein recommended the third search and identified a relevant study that was not otherwise identified (personal communication, September 22–25, 2001). The search strategies included (1) the term Masling combined with orality or oraldepen*, (2) Robert F. Bornstein as an author of any study, and (3) the term Rorschach combined with Samuel Juni as an author. In total, these searches identified 168 nonduplicate articles, 89 of which appeared likely to contain relevant data. These studies were obtained and r, kappa, or ICC results were obtained from 37. However, to ensure that only independent samples contributed data, when different studies reported the same reliability N, the same reliability value, and the same type of participants, only one sample was allowed into the analyses. In the end, data were obtained from 31 studies and 40 samples (Table 25.1, Entry 3). A complete list of citations is in the Appendix.
To identify studies on RPRS interrater reliability, I searched PsycINFO for English-language articles that contained prognostic-rating-scale combined with Rorschach or Klopfer. Thirty-five studies were identified. Seven additional studies were obtained from Goldfried, Stricker, and Weiner’s (1971) early review of this literature or Meyer and Handler’s (1997) meta-analysis. Out of these 42 studies, 8 provided interrater coefficients that could be cumulated (Table 25.1, Entry 19). Data came from Cooper, Adams, and Gibby, (1969; estimated from the range reported); Edinger and Weiss (1974); Endicott and Endicott (1963; pre- and posttreatment samples); Hathaway (1982); Newmark, Finkelstein, and Frerking (1974; pre- and posttreatment samples); Newmark, Hetzel, Walker, Holstein, and Finkelstein (1973; pre- and posttreatment samples); Newmark, Konanc, Simpson, Boren, and Prillaman (1979); and Williams, Monder, and Rychlak (1967).
TAT Scales
Three new meta-analyses were conducted to summarize the interrater reliability of TAT scoring. Although there are many TAT scales described in the literature, several of which have been studied extensively (e.g., the Achievement, Intimacy, and Power motives), the scales examined here have been actively researched in clinical samples over the past several years. They include the Defense Mechanism Manual (DMM), the Social Cognition and Object Relations Scale (SCORS), and the Personal Problem-Solving Scale (PPSS).
To identify relevant data, I initially searched PsycINFO for all English-language studies published after 1989 that included the term thematic-apperception-test. This search identified 172 articles; 11 had reliability data on the SCORS, 7 contained data for the DMM, and 2 had data for the PPSS. Next, these articles were used to identify additional, nonredundant reliability studies. Nine additional sources were found for the DMM (Table 25.1, Entry 20), four more were found for the SCORS (Table 25.1, Entry 18), and one new study was found for the PPSS (Table 25.1, Entry 11). A list of the 16 DMM studies and 15 SCORS citations can be found in the Appendix.
For the PPSS, Pearson correlations were obtained from the three samples in Ronan, Colavito, and Hammontree (1993) and the two samples in Ronan et al. (1996). ICC results were obtained from the two studies reported in Ronan, Date, and Weisbrod (1995).
The Hamilton Rating Scales
To identify studies examining the interrater reliability of the HDRS and HARS, the English-language literature on Psyc-INFO and PubMed was searched by combining the scale names with the terms reliability or agreement. A total of 168 unique citations were identified. Based on the article abstracts, 52 of these appeared likely to contain relevant data. In addition, the text and bibliographies in these articles were searched for other relevant publications, which produced 25 new citations. In total, 77 articles were examined for relevant HDRS and HARS data, including Hedlund and Vieweg’s (1979) review of HDRS research. Studies were excluded if they were missing information required for aggregation (e.g., N; type of reliability design; r, kappa, or ICC as an effect size). One additional study was omitted. Gottlieb, Gur, and Gur (1988) reported an intraclass correlation of .998. However, their mean HDRS score was approximately 3.0 (SD ” 4.5) and the exact agreement rate was approximately 60%, with raters differing by up to 5 raw score points. The latter findings appear incompatible with an ICC of .998. In the end, 51 citations provided relevant information. A complete list organized by test can be found in the Appendix.
To summarize HDRS and HARS reliability, results were partitioned into designs in which clinicians based their ratings on separate interviews and those in which ratings were based on the same fixed source of information. The latter category included instances when both raters were present for the same interview, when one or more raters viewed a videotape, and when the patient’s self-report fully determined both sets of ratings being compared (e.g., the patient completed the scale in writing and then was asked the same questions in a highly structured oral format; the patient was given a highly structured personal interview and then immediately thereafter was asked the same highly structured questions via the telephone).
Designs that rely on separate interviews can be confounded by the time lapse between interviews. As this delay increases, greater changes in the patient’s emotional state should be expected, which would reduce reliability for reasons unrelated to rater agreement. Thus, separate interview studies were excluded if the retest interval exceeded the time frame of the ratings. For instance, although joint interview results were used from Potts, Daniels, Burnam, and Wells (1990), their separate interview results were excluded. In this study, subjects reported on their affect over the past month. However, the average interval between the first and second interviews was 15 days with an SD of 11 days, suggesting that in a salient proportion of interviews the patient would have been describing his or her mood over distinct time frames.
Peer Review of Research
To identify studies examining the interrater reliability of the scientific peer-review process, I searched the English-language literature using PsycINFO and PubMed. For PsycINFO, the terms peer-review or manuscript-review were combined with the terms reliability or agreement. For PubMed, the MeSH category of peer review was combined with the MeSH categories of reproducibility of results or observer variation and results were limited to citations containing an abstract. A total of 159 unique citations were found, 34 of which appeared likely to contain relevant data based on the abstract. In addition, 34 new citations were found by reviewing these articles for other relevant studies. In total, 68 articles were examined in detail, including Cicchetti’s (1991) major review, which contained results from 26 samples of manuscript or grant submissions. When it was necessary to obtain information not included in Cicchetti’s review (e.g., N), the original citations were obtained.
My initial goal was to update Cicchetti’s (1991) review of agreement between two peer reviewers. However, studies have examined other aspects of reliability related to scientific peer review. For instance, Justice, Berlin, Fletcher, Fletcher, and Goodman (1994) examined the extent to which different types of physicians agreed on the quality of manuscripts slated to be published in the Annals of Internal Medicine. Ratings of quality made by journal readers who expressed interest in the article’s topic were compared to ratings from (1) other journal readers who expressed the same interest (weighted kappa ” .05; N ” 159), (2) standard peer reviewers for the journal (weighted kappa ” !.02; N ” 352), and (3) experts in the relevant area of research (weighted kappa ” !.01; N ” 371). Although these findings suggest that different consumers of the research literature have very different views on the quality of published studies, because this was the only investigation of its kind, the results were not included in Table 25.1. However, two other types of designs occurred more frequently and their results were aggregated. In one design, used in five samples, the mean ratings obtained from one panel of grant reviewers were compared to the mean ratings obtained from a second, independent panel of grant reviewers. When interpreting these results, it should be kept in mind that ratings averaged across multiple raters sharply curtail the random error that would be associated with any single rater. Thus, results from these averaged ratings will produce markedly higher reliability coefficients than would be obtained from any two individual grant reviewers (e.g., Scullen, 1997). The second type of reliability design, used in five studies, investigated the extent to which editors agreed with each other on the quality of the reviews submitted by manuscript reviewers.
Ultimately, reliability data addressing aspects of the peerreview process were obtained from 34 citations. Virtually all of the excluded citations did not contain relevant reliability data, though Das and Froehlich’s (1985) findings on reviewer agreement were excluded because they used an ICC formula that differed from standard formulas (McGraw & Wong, 1996), and Gottfredson’s (1978) findings were not used because the design relied on previously published articles as well as raters who were nominated by the original authors.
To summarize the reliability of peer reviewers (Table 25.1, Entry 42), various forms of scientific review were combined, including journal or conference submissions, grant applications, and submissions to research ethics committees or institutional review boards. Results were partitioned into dimensional ratings and dichotomous decisions. If a study did not report a relevant coefficient but provided raw data, results were computed from that information. Many studies addressing manuscript review examined publication recommendations as well as more specific questions, such as the quality of the literature review or appropriateness of the analyses. Within a study, the most direct measure of overall merit was used here. Doing so produced slightly higher estimates of reliability (p # .0005). For studies reporting both types of results, direct ratings of quality had a mean reliability of .26 (N ” 10,514), while ratings for more specific items had a reliability of .23 (N ” 9,695). Finally, if a study presented both unweighted kappa and weighted kappa or an ICC, the weighted kappa or ICC was used in the analyses. A list of final studies providing peer-reviewer agreement data is provided in the Appendix.
With respect to agreement among editors on the quality of peer reviewers or their submitted reviews (Table 25.1, Entry 25), one study used the Pearson correlation (van Rooyen, Godlee, Evans, Black & Smith, 1999). The four studies that contributed chance-corrected reliability statistics were Callaham, Baxt, Waeckerle, and Wears (1998); Feurer et al. (1994); van Rooyen, Black, and Godlee (1999); and Walsh, Rooney, Appleby, and Wilkinson (2000).
Studies that examined agreement between the mean ratings of one panel of grant reviewers and the mean ratings from a separate panel of reviewers (Table 25.1, Entry 36) were partitioned into dimensional ratings and dichotomous determinations (i.e., fund vs. not). The four studies that contributed correlations for dimensional ratings were Hodgson (1995, 1997); Plous and Herzog (2001; from raw data); and Russell, Thorn, and Grace (1983; omitting the confounded panel A with panel D data). The three studies that contributed chance-corrected statistics for dimensional ratings were Hodgson (1995, 1997) and Plous and Herzog (2001). The studies that contributed chance-corrected statistics for dichotomous funding decisions were Cicchetti (1991) and Hodgson (1997).
Cattell’s Scree Plots
To identify articles containing interrater reliability data for using Cattell’s scree plot to determine the proper number of factors to extract in a factor analysis or cluster analysis, the English-language literature on PsycINFO was searched using the terms scree-plot or scree-test and reliability or agreement. Eleven articles were identified. Three of these provided relevant data and their bibliographies identified a fourth study (Table 25.1, Entry 38). ICCs were obtained from Cattell and Vogelmann (1977; from raw data), Crawford and Koopman (1979), Lathrop and Williams (1987), and Streiner (1998). Two of the studies investigated the influence of factor analytic expertise and found no differences between experts and novices who had been provided with some training. Nonetheless, the summary results should be treated cautiously because reliability varied widely across studies, ranging from a low of .00 to a high of .89.
Summary of Meta-Analytic Studies of Interrater Reliability
The interrater reliability meta-analyses examine a diverse set of topics. The targeted constructs vary substantially in their complexity and in the methods used to obtain measurements (e.g., physical measurements with a ruler vs. application of complex theoretical constructs to narrative productions). The constructs also range from scoring tasks that code very discrete or circumscribed events (e.g., Entries 1 through 5) to interpretive tasks that code more abstract or higher level inferences (e.g., Entries 24, 32, 37, 39, and 42). Nonetheless, in the context of this chapter, the main point embedded in Table 25.1 appears clear. The interrater reliability observed when coding Rorschach or TAT protocols falls in the range between .80 and .91. This level of agreement compares favorably with the reliability seen for a wide range of other determinations made in psychology and medicine.2
Also, from a purely psychometric perspective, the findings in Table 25.1 indicate that scales generally are more reliable than items. Although it is a gross comparison, in the 17 instances when these levels of measurement could be directly compared, scales had an average reliability of .77, while items had an average reliability of .62. Thus, aggregated determinations that mathematically combine lower level judgments are more reliable than single observations. Surprisingly, while chance-corrected statistics did produce somewhat lower estimates of reliability than correlations, the difference was not large. Across the 16 topics that provided both types of statistics, the average kappa/ICC was .70 and the average correlation was .74.
Overall, the data in Table 25.1 do not support the notion that interrater reliability coefficients for the Rorschach or TAT are deficient relative to other tests or applied judgments in psychology and medicine. However, it remains possible that psychometric deficiencies will be evident when considering other types of systematically collected data. To address this prospect, evidence on test-retest reliability will be examined and then evidence on test validity.
META-ANALYSES OF TEST-RETEST RELIABILITY
For any variable that is thought to measure a stable characteristic, evidence on test-retest reliability is very pertinent because it indicates whether the test scale validly measures a traitlike feature of the person rather than a transient statelike quality. One could wonder if tests like the Rorschach or TAT show comparatively less traitlike consistency than other personality tests.
To identify meta-analyses examining stability over time, I searched the English-language literature on PsycINFO and PubMed. In both databases, the terms test-retest, retestreliability, retest-stability, stability and reliability, or stability and consistency were combined with terms restricting the search to meta-analyses or systematic literature reviews. In total, 101 unique studies were identified. Based on the abstracts, 19 articles seemed likely to contain aggregated retest coefficients and these were obtained. In addition, I summarized any systematically gathered retest data that had been reported in the interrater reliability meta-analyses discussed above. Three of those studies presented relevant data (Gosling, 2001; Yarnold & Mueser, 1989; Zimmerman, 1994), though one had also been identified in the search for stability studies.3
Of the 21 relevant studies, several were excluded. Two examined statelike variables (i.e., depression and happiness), three others were superseded by more recent and comprehensive meta-analyses, and one did not provide a quantitative summary of the literature. From the final group of 15 metaanalyses, 2 provided stability coefficients for performance tests of personality (Parker, Hanson, & Hunsley, 1988; Roberts & DelVecchio, 2000). Results from all the meta-analyses are presented in Table 25.2 and each will be described briefly.
Roberts and DelVecchio (2000) completed a comprehensive meta-analysis on the long-term stability of personality traits. They relied on data from nonclinical samples and excluded studies with a retest interval of less than 1 year, leaving them with a final sample of 152 longitudinal studies that had an average retest interval of 6.7 years. The authors subsequently categorized personality tests into three types of methods using data from 135 samples. Rorschach, TAT, and sentence completion scales were treated as one method category, self-report scales comprised a second category, and observer rating scales formed the final category. As indicated in Table 25.2 (Entry 1), after statistically adjusting for sample age and fixing the estimated retest interval to 6.7 years, they found retest correlations of .45 for the Rorschach, TAT, or SCT; .50 for self-reports; and .51 for observer ratings. While encouraging more research, the authors concluded “Given the small magnitude of the difference, we feel the most impressive feature of these analyses is the lack of substantive differences between the three primary methods of assessing traits” (p. 16).
Parker, Hanson, and Hunsley (1988) reached a similar conclusion. They examined the 1970 to 1981 journal literature and compared stability for the Rorschach, Wechsler Adult Intelligence Scale (WAIS), and Minnesota Multiphasic Personality Inventory (MMPI). Although they did not report average retest intervals, reliability was .74, .82, and .85 for the MMPI, WAIS, and Rorschach, respectively (Table 25.2, Entry 16).
Of the remaining meta-analyses, Ashton (2000) examined the retest reliability of professional judgments in medicine, psychology, meteorology, human resources, and business (mainly accounting). These studies examine intrarater reliability and quantify the extent to which the same professional evaluates the same information equivalently at two different points in time. Following Ashton, studies that obtained both judgments in the same experimental session were omitted, relying instead on just those findings he classified as indic-
326 Reliability and Validity
TABLE 25.2 Meta-Analyses of Test-Retest Reliability From the Psychological Literature
| Mean retest | N of | Test-retest r | ||||
|---|---|---|---|---|---|---|
| interval in | TAT, SCT, | Other | ||||
| Study/test or method | months | Samples | Subjects | or Rorschach | tests | |
| 1. Roberts and DelVecchio (2000); Personality Traits, Controlling for Age and Retest Durationa |
||||||
| Observer rating | 80.4 | 54 | 11,662 | .51 | ||
| Self-report | 80.4 | 73 | 46,196 | .50 | ||
| Rorschach, TAT, or SCT | 80.4 | 8 | 1,083 | .45 | ||
| 2. Schuerger and Witt (1989); Individually Tested IQb | ||||||
| Adults aged 18–24 | 72.0 | 79 | — | .79 | ||
| Children aged 6–9 | 72.0 | 79 | — | .72 | ||
| 3. Holden and Miller (1999); Parental Child Rearingc | ||||||
| Self-reported beliefs | 82.7 | 10 | 875 | .50 | ||
| Observed and self-reported | 36.4 | 47 | 3,786 | .45 | ||
| Observed behaviors | 18.4 | 33 | 2,587 | .41 | ||
| Observed behaviors | !1 | 11 | — | .59 | ||
| 4. van Ijzendoorn, Schuengel, and Bakermans-Kranenburg (1999); Disorganized Child | ||||||
| Parent Attachment | 25.2 | 14 | 840 | .34 | ||
| 5. Viswesvaran and Ones (2000); “Big Five” Personality Scales (Ms across 5 scales)d | 19.5 | 170 | 41,074 | .73 | ||
| 6. Gosling (2001); Mammal Personality Traits | ||||||
| Items | 18.6 | 4 | 64 | .46 | ||
| Scales | 12.0 | 1 | 12 | .92 | ||
| 7. Schuerger and Witt (1989); Individually Tested IQb | ||||||
| Adults aged 18–24 | 12.0 | 79 | — | .85 | ||
| Children aged 6–9 | 12.0 | 79 | — | .80 | ||
| 8. Zimmerman (1994); DSM Personality Disorderse | 7.1 | 7 | 457 | .44 | ||
| 9. Holland, Johnston, and Asama (1993); Self-Report Vocational Identity Scalef | 5.4 | 13 | 1,708 | .68 | ||
| 10. Swain and Suls (1996); Physiological Reactivity to Stressorsg | ||||||
| Heart rate | 3.0 | 95 | — | .55 | ||
| Blood pressure | 3.8 | 73 | — | .38 | ||
| 11. Ashton (2000); Professional Judgments (Intrarater Stability)h | ||||||
| Medicine and psychology | 4.1 | 6 | 1,997 | .73 | ||
| Human resources | 2.7 | 11 | 36,712 | .73 | ||
| Business | 1.7 | 3 | 2,576 | .82 | ||
| Meteorology | 1.6 | 2 | 300 | .87 | ||
| All studies | 2.9 | 22 | 41,585 | .76 | ||
| 12. McKelvie (1995); Self-Reported Vividness of Visual Imageryi | 1.3 | 7 | — | .74 | ||
| 13. Schuerger and Witt (1989); Individually Tested IQb | ||||||
| Adults aged 18–24 | 1.0 | 79 | — | .92 | ||
| Children aged 6–9 | 1.0 | 79 | — | .83 | ||
| 14. Yarnold and Mueser (1989); Type A Behavior | ||||||
| Structured Interview | — | 1 | — | .68 | ||
| Jenkins Activity Survey | — | 7 | — | .71 | ||
| 15. Shulman (2000); Clock Drawings for Cognitive Impairment | — | 4 | 277 | .76 | ||
| 16. Parker, Hanson, and Hunsley (1988); Common Psychological Tests | ||||||
| Rorschach | — | 2 | 125 | .85 | ||
| WAIS | — | 4 | 93 | .82 | ||
| MMPI | — | 5 | 171 | .74 | ||
| 17. Capraro, Capraro, and Henson (2001); Mathematics Anxiety Rating Scale (Self-Report) | — | 7 | — | .84 | ||
a The number of subjects was obtained from the data reported in their Table 1. However, the values reported here are slight overestimates because they are based on 65 observer rating samples; 80 self-report samples; and 9 Rorschach, TAT, or SCT samples.
b The reported values are from regression estimates for specified ages and retest intervals using data from 79 samples.
c Retest intervals for the first three coefficients and Ns for the first and third were obtained from raw data in their Table 4.
d The estimated retest interval was computed as a weighted average across the five scales. Total sample size was estimated from the mean sample size across the 158 studies that provided this information.
e Reliability is reported using the kappa coefficient, not r.
f Nonindependent samples were excluded.
g Average retest duration was estimated from data reported in their Table 3, assigning an estimate of 2 years to studies that were simply described as being longer than 1 year.
h The average retest duration and N were obtained from data reported in his Table 1. Virtually all studies used a multirater design, so the reported N was computed as n(k ! 1).
i The average retest interval was estimated as the midpoint of the range across studies (i.e., 3 to 7 weeks). ative of stability (Table 25.2, Entry 11). Capraro, Capraro, and Henson (2001) examined stability for the self-report Mathematics Anxiety Rating Scale. Few details were provided about the seven retest samples in this review (Table 25.2, Entry 17). Gosling’s (2001) review of animal behavior traits provided stability data for one small study using scale-level ratings and four small samples using item-level ratings (Table 25.2, Entry 6).
Holden and Miller (1999) examined the stability of parental child-rearing beliefs and behaviors. Beliefs were assessed with self-report inventories and behaviors were observed and coded by others. Although their primary interest was in studies with retest intervals greater than 1 month, they also provided the median reliability from 11 short-term observational studies (Table 25.2, Entry 3). Holland, Johnston, and Asama (1993) presented a table of quantitative findings on the stability of the Vocational Identity Scale, which measures one’s propensity to have clear and stable goals, interests, and talents (Table 25.2, Entry 9). McKelvie (1995) summarized the shortterm stability findings for the self-rated Vividness of Visual Imagery Questionnaire (Table 25.2, Entry 12). Schuerger and Witt (1989) examined the stability of measured intelligence using the Wechsler scales and the Stanford-Binet. Data from 79 child and adult samples retested over various intervals were used to develop regression equations that predicted stability as a function of age and retest duration. For the findings in Table 25.2, two sets of ages and three time intervals were selected to illustrate stability (Table 25.2, Entries 2, 7, and 13).
Swain and Suls (1996) examined the stability of physiological changes in response to laboratory stressors. They presented findings separately for heart rate, systolic blood pressure, and diastolic blood pressure, though the blood pressure results were averaged for Table 25.2 (Entry 10). Shulman (2000) presented a table of quantitative findings regarding the stability of clock drawings as a neuropsychological procedure to quantify cognitive impairment (Table 25.2, Entry 15). When aggregating information from this review, it was assumed that the reported Ns indicated the number of subjects included in the reliability analyses. Van Ijzendoorn, Schuengel, and Bakermans-Kranenburg (1999) conducted a meta-analysis on the stability of the disorganized pattern of child-parent attachment (Table 25.2, Entry 4).
Viswesvaran and Ones (2000) provided a comprehensive examination of self-report personality inventories that are currently used in personnel selection. Findings for nonpatient samples were obtained from the technical manuals for 24 tests and results were organized in the framework of the Five-Factor Model (Table 25.2, Entry 5). Yarnold and Mueser’s (1989) review of Type A measures provided summary data from seven samples that used the self-report Jenkins Activity Survey and one sample that used the Structured Interview for Type A behavior (Table 25.2, Entry 14). Finally, Zimmerman (1994; supplemented by the additional data reported in Loranger et al., 1994) provided retest findings from seven samples in which structured interviews were used to assess DSM personality disorders over moderately long intervals (Table 25.2, Entry 8).
Findings in Table 25.2 have been roughly organized by retest duration, with longer intervals at the top of the table. The three studies that did not report retest durations are listed at the bottom of the table. Based on the information available, when looking across studies, the length of the retest interval tends to be negatively related to stability (r ” !.34, N ” 27; p ” .078), which is consistent with findings from most of the larger meta-analyses (e.g., Roberts & DelVecchio, 2000; Schuerger & Witt, 1989). However, in Table 25.2 the magnitude of the association between longer retest intervals and lower retest reliability is not as strong as might be anticipated. This may be due to the fact that some constructs are less stable than others (e.g., interview-based personality disorder diagnoses may be less stable than test-derived personality traits) or to methodological variables. For instance, items should be less stable than scales (e.g., Gosling’s item-level findings vs. Roberts and DelVecchio’s scale-level findings), dichotomous determinations may be less stable than scores on a graduated continuum (e.g., Zimmerman’s dichotomous diagnoses vs. Roberts and DelVecchio’s continuous traits), and chance-corrected reliability coefficients (i.e., Zimmerman’s findings) likely produce lower estimates of stability than correlations. Furthermore, many of the findings in Table 25.2 are based upon a small number of observations. This is particularly true for the findings reported in Gosling (2001) and for the Structured Interview coefficient reported by Yarnold and Mueser (1989). Caution is also warranted with Parker et al.’s (1988) findings, particularly for the Rorschach and WAIS.
Keeping these limitations in mind, it remains the case that Table 25.2 provides no support for the idea that tests like the Rorschach, TAT, or SCT are less stable than other instruments. In fact, the two systematic reviews that examined testretest reliability for both performance tests of personality and other testing methods found roughly comparable results across methods. Thus, the overall pattern of findings in Table 25.2 is quite similar to that observed in Table 25.1. The existing systematically gathered evidence does not suggest that performance tests of personality have deficient stability relative to other types of personality assessment instruments.
Nonetheless, it is possible that the genuine limitations associated with these tests will be evident when validity data is considered. Even though different kinds of reliability findings may be comparable across tests, performance measures of personality like the Rorschach and TAT may be notably deficient when considering the ultimate question of test validity.
META-ANALYSES OF TEST VALIDITY
Recently, Meyer et al. (2001) presented 133 meta-analytically derived validity coefficients for psychological and medical tests. Meyer and Archer (2001) extended that overview by computing 20 new or refined meta-analytic validity coefficients for the Rorschach, MMPI, and Wechsler intelligence tests. Table 25.3 provides findings from these sources. The table includes the 38 Rorschach, MMPI, and IQ validity coefficients that were reported in Meyer and Archer’s summary table (their Table 4), all the thematic story and self-report validity coefficients from Bornstein’s (1998c, 1999) metaanalyses on dependency, and all the other thematic story and sentence completion validity coefficients that were reported in Table 2 of Meyer et al. (2001). Because this selection process provided a wide range of validity data for the MMPI and intelligence tests, Meyer et al.’s results for other psychological tests were not reproduced here. However, to provide a representative sampling of medical test validity, every third finding was selected from the 63 medical validity coefficients listed in Table 2 of Meyer et al.
When considering Table 25.3, it is important to keep several caveats in mind. First, all examples make use of coefficients that were not corrected for unreliability, range restriction, or the imperfect construct validity of criterion measures. Second, all the coefficients do not come from equivalent designs. Some studies selected extreme groups of participants; examined rare, low base rate events; artificially dichotomized truly continuous variables; employed relatively small samples; or used procedures not typically found in applied clinical practice. These methodological factors can influence validity coefficients and make them systematically differ in size (Hunter & Schmidt, 1990). Thus, even though table entries are organized by magnitude, differences in ranking cannot be taken to mean that one test is globally better than another.
With these points in mind, the data in Table 25.3 lead to several observations (Meyer & Archer, 2001; Meyer et al., 2001). First, both psychological and medical tests have varying degrees of validity, ranging from tests that are essentially unrelated to a criterion, to tests that are strongly associated with relevant criteria. Second, it is difficult to distinguish the validity coefficients for psychological and medical tests. These tests do not cluster at different ends of the validity continuum but instead produce coefficients that are interspersed throughout its range. Third, test validity is conditional. A given test produces stronger validity for some criteria and weaker validity for other criteria. Finally, as with the interrater and retest reliability data in Tables 25.1 and 25.2, the broad review of systematically collected validity data in Table 25.3 does not reveal uniformly superior or uniformly inferior methods of psychological assessment.
Despite the arguments and criticisms that have been leveled against performance-based tests of personality, the Rorschach, TAT, and SCT do not produce noticeably lower validity coefficients than alternative personality tests. Instead, performance tests of cognitive ability, performance tests of personality, and self-report tests of personality all produce a range of validity coefficients that vary largely as a function of the criterion under consideration.
SUMMARY CONCLUSIONS
The purpose of this chapter was to provide a sound and thorough examination of systematically gathered evidence addressing the psychometric properties of tests like the Rorschach and TAT. More than any other personality assessment instruments, these kinds of measures have been harshly criticized. In fact, recent arguments about their psychometric defects have been accompanied by rallying cries for attorneys to attack their use whenever possible and for psychologists to banish them from applied clinical practice (e.g., Garb, 1999; Grove & Barden, 1999; Lilienfeld et al., 2000; Wood et al., 2000). The latter are dramatic calls for action. Given that these proposals are presented as recommendations emerging from the scientific literature, one should anticipate that the systematically gathered evidence on reliability and validity would unambiguously demonstrate how inferior these methods of personality assessment really are. However, the metaanalytic evidence does not provide such a demonstration. If anything, the findings reveal the opposite. The Rorschach, TAT, and SCT produce reliability and validity coefficients that appear indistinguishable from those found for alternative personality tests, for tests of cognitive ability, and for many medical assessment procedures.
At the same time, there are limitations to the data presented in this chapter that should be appreciated. Considering Table 25.1, it is likely that some approaches to scoring tests like the Rorschach or TAT are less reliable than those included in this table. (Of course, some are likely to be more reliable as well.) However, the Rorschach and TAT scales in the table were not selected because of the reliability results they produced. They were selected because they have all been part of recent publications addressing clinical topics. As such,
TABLE 25.3 Summary Effect Sizes (r) From Meta-Analyses Examining Test Validity
| Predictor test and criterion | Rorschach, TAT, or SCT |
Other psych test |
Medical test |
N |
|---|---|---|---|---|
| 1. Dexamethasone Suppression Test Scores and Response to Depression Treatment | .00 | 2,068 | ||
| 2. Routine Ultrasound Examinations and Successful Pregnancy Outcomes | .01 | 16,227 | ||
| 3. MMPI Ego Strength Scores and Subsequent Psychotherapy Outcome | .02 | 280 | ||
| 4. Unique Contribution of an MMPI High Point Code (vs. Other Codes) to Relevant Criteriaa | .07 | 8,614 | ||
| 5. MMPI Scores and Subsequent Prison Misconduct | .07 | 17,636 | ||
| 6. MMPI Elevations on Scales F, 6, or 8 and Criminal Defendant Incompetency | .08 | 1,461 | ||
| 7. In Cervical Cancer, Lack of Glandular Differentiation on Tissue Biopsy and 5# Year Survival | .11 | 685 | ||
| 8. MMPI Scale 8 and Differentiation of Schizophrenic versus Depressed Disorders | .12 | 2,435 | ||
| 9. Lower General Cognitive Ability and Involvement in Automobile Accidents | .12 | 1,020 | ||
| 10. General Intelligence and Success in Military Pilot Training | .13 | 15,403 | ||
| 11. Rorschach DEPI and Detection of Depressive Diagnosis | .14 | 994 | ||
| 12. MMPI Scale 2 and Differentiation of Neurotic versus Psychotic Disorders | .14 | 6,156 | ||
| 13. MMPI Scale 8 and Differentiation of Neurotic versus Psychotic Disorders | .14 | 6,156 | ||
| 14. Baseline IQ and Subsequent Psychotherapy Outcome | .15 | 246 | ||
| 15. Low Serotonin Metabolites in Cerebrospinal Fluid (5-HIAA) and Subsequent Suicide Attempts | .16 | 140 | ||
| 16. MMPI Cook-Medley Hostility Scale Elevations and Subsequent Death From All Causes | .16 | 4,747 | ||
| 17. Motivation to Manage from the Miner Sentence Completion Test and Managerial Effectiveness | .17 | 2,151 | ||
| 18. MMPI Validity Scales and Detection of Known or Suspected Under-Reported Psychopathology | .18 | 328 | ||
| 19. Dexamethasone Suppression Test Scores and Subsequent Suicide | .19 | 626 | ||
| 20. Self-Reported Dependency Test Scores and Physical Illness | .21 | 1,034 | ||
| 21. Rorschach to Detect Thought Disturbance in Relatives of Schizophrenic Patients | .22 | 230 | ||
| 22. MMPI Dependency Scale and Dependent Behavior | .22 | 320 | ||
| 23. TAT Scores of Achievement Motivation and Spontaneous Achievement Behavior | .22 | (k ” 82) | ||
| 24. Traditional Electrocardiogram Stress Test Results and Coronary Artery Disease | .22 | 5,431 | ||
| 25. WISC Distractibility Subscales and Learning Disability Diagnoses | .24 | (K ” 54) | ||
| 26. Decreased Bone Mineral Density and Lifetime Risk of Hip Fracture in Women | .25 | 20,849 | ||
| 27. General Intelligence Test Scores and Functional Effectiveness Across Jobs | .25 | 40,230 | ||
| 28. Self-Reported Dependency Test Scores and Dependent Behavior | .26 | 3,013 | ||
| 29. Thematic Story Test Dependency Scores and Recalled Physical Illness | .29 | 269 | ||
| 30. C-Reactive Protein Test Results and Diagnosis of Acute Appendicitis | .28 | 3,338 | ||
| 31. General Validity of Rorschach Studies Without Method Confounds | .29 | 6,520 | ||
| 32. General Validity of MMPI Studies Without Method Confounds | .29 | 15,985 | ||
| 33. For Women, Electrocardiogram Stress Test Results and Detection of Coronary Artery Disease | .30 | 3,872 | ||
| 34. MMPI Scale 2 and Differentiation of Schizophrenic versus Depressed Disorders | .31 | 2,435 | ||
| 35. General Validity of Rorschach Hypotheses Without Method Confounds | .32 | (k ” 523) | ||
| 36. General Validity of MMPI Hypotheses (Includes Some Method Confounds) | .32 | (k ” 533) | ||
| 37. Screening Mammogram Results and Detection of Breast Cancer Within 1 Year | .32 | 263,359 | ||
| 38. General Validity of WAIS Studies Without Method Confounds | .33 | 3,593 | ||
| 39. MMPI Scale 2 or DEP and Detection of Depressive Diagnosis | .35 | 2,905 | ||
| 40. Incremental Contribution of Rorschach PRS Scores Over IQ to Predict Treatment Outcome | .36 | 290 | ||
| 41. General Validity of WAIS Hypotheses Without Method Confounds | .36 | (k ” 104) | ||
| 42. Papanicolaou Test (Pap Smear) and Detection of Cervical Abnormalities 43. Competency Screening Sentence Completion Test Scores and Defendant Competency |
.37 | .36 | 17,421 627 |
|
| 44. Rorschach Oral Dependence Scale and Dependent Behavior | .37 | 1,320 | ||
| 45. Sperm Penetration Assay Results and Success With in Vitro Fertilization | .39 | 1,335 | ||
| 46. MMPI Validity Scales to Detect Under-Reported Psychopathology (Primarily Analog Studies) | .39 | 2,297 | ||
| 47. Computed Tomography Results and Detection of Lymph Node Metastases in Cervical Cancer | .41 | 1,022 | ||
| 48. MMPI Scale 8 and Differentiation of Psychiatric Patients versus Controls | .42 | 23,747 | ||
| 49. Conventional Dental X-rays and Diagnosis of Between-Tooth Cavities (Approximal Caries) | .43 | (K ” 8) | ||
| 50. Rorschach SCZI and Detection of Psychotic Diagnosis | .44 | 717 | ||
| 51. MMPI Scale 2 and Differentiation of Psychiatric Patients versus Controls | .44 | 23,747 | ||
| 52. WAIS IQ and Obtained Level of Education | .44 | (k ” 9) | ||
| 53. Digitally Enhanced Dental X-rays and Diagnosis of Biting Surfaces Cavities | .44 | 2,870 | ||
| 54. Rorschach PRS Scores and Subsequent Psychotherapy Outcome | .45 | 624 | ||
| 55. MMPI Validity Scales and Detection of Known or Suspected Malingered Psychopathology | .45 | 771 | ||
| 56. Thematic Story Test Dependency Scores and Dependent Behavior | .46 | 448 | ||
| 57. Rorschach X#% and Differentiation of Clinical or Target Groups From Controls | .46 | 1,517 | ||
| 58. Antineutrophil Cytoplasmic Antibody Testing and Detection of Wegener Granulomatosis | .47 | 13,562 | ||
| 59. Lecithin/Sphingomyelin Ratio and Prediction of Neonatal Respiratory Distress Syndrome | .50 | 1,170 | ||
(continued)
TABLE 25.3 (Continued)
| Predictor test and criterion | Rorschach, TAT, or SCT |
Other psych test |
Medical test |
N |
|---|---|---|---|---|
| 60. WAIS IQ Subtests and Differentiation of Dementia From Normal Controls | .52 | 516 | ||
| 61. MRI Results and Detection of Ruptured Silicone Gel Breast Implants | .53 | 382 | ||
| 62. MRI Results and Differentiation of Dementia From Normal Controls | .57 | 374 | ||
| 63. Computed Tomography Results and Detection of Metastases From Head and Neck Cancer | .64 | 517 | ||
| 64. MMPI Validity Scales and Detection of Malingered Psychopathology (Primarily Analog Studies) | .74 | 11,204 | ||
| 65. MMPI Basic Scales: Booklet versus Computerized Form | .78 | 732 | ||
| 66. Creatinine Clearance Test Results and Kidney Function (Glomerual Filtration Rate) | .83 | 2,459 |
Note. Original citations for most table entries can be found in Meyer et al. (2001). However, source information for Entries 8, 11–14, 21, 22, 31, 32, 34–36, 38, 39, 41, 44, 48, 50, 51, and 57 can be found in Meyer and Archer (2001) and Entries 29 and 56 were obtained from Bornstein (1998c, 1999). K ” number of samples; k ” number of effects.
a The design in this research should produce results more akin to incremental validity than univariate validity.
there is no reason to believe their meta-analytic findings provide biased estimates of interrater reliability. It is also the case that Table 25.1 does not provide a comprehensive inventory of meta-analytic findings on interrater reliability. This is because the evidence has yet to be summarized for the vast majority of assessment procedures in psychology, psychiatry, and medicine. For instance, the table contains no summary data on sentence completion tests or alternative performance tasks of personality (e.g., figure drawings), and it contains no results for cognitive ability measures, global functioning scales, MRI readings, or tissue sample classifications.
The Table 25.2 findings on retest reliability also are not definitive. The Rorschach, TAT, and SCT results emerge from a relatively small pool of retest studies, none of which examined all the various scales that can be derived from these instruments. Furthermore, the evidence for these instruments is too limited to address potential moderators of stability, such as age, gender, scale distributions, engagement with the task, and so on. However, the same limitations are present for other psychological and medical measures, the vast majority of which have never been examined in a meta-analysis or perhaps ever studied in a retest design.
Finally, the validity coefficients in Table 25.3 do not encompass all the individual validity findings in the literature, or even all the topics that have been the subject of frequent validation research. In addition, the table presents information on just a limited number of instruments. For each instrument only a limited subset of hypothesized associations are typically included in the meta-analytic findings. Thus, the results in this table are far from exhaustive. These limitations exist not just for the Rorschach or TAT but for all psychological and medical tests.
At present, it seems fair to say that all assessment procedures have an incomplete evidentiary foundation relative to the diverse ways they are used in applied practice. Nevertheless, the findings in all three tables serve a valuable purpose. They emerge from systematic evidence gathered across a range of instruments and therefore provide a compelling snapshot of typical psychometric properties in the research literature.
When taken together, this compilation of meta-analyses on interrater reliability, test-retest reliability, and validity have direct implications for the recent criticisms that have been leveled against performance-based tests of personality. These criticisms often take one of two forms: (1) pointing out how some relevant questions have yet to be studied or conclusively answered and (2) scrutinizing individual studies to identify potential methodological problems. Both types of criticism can be problematic.
In any scientific endeavor, from psychology to physics, one can always identify questions that remain understudied, unanswered, or unresolved. This is true regardless of the scope and quality of the existing evidence base. Thus, when considering that which is not yet known about assessment procedures, one must also appreciate the knowledge base that does exist, as well as the way in which unanswered questions pervade all domains of science.
Second, because criticism comes easier than craftsmanship, flaws or shortcomings can always be identified for an individual study. Indeed, the last entry in Table 25.1 documents that interrater reliability for the scientific peer-review process is very poor. This finding reveals how scientists have markedly different opinions about the merits and strengths of individual research projects. What one scientist considers a sound and valuable study is regularly seen by another scientist to be a weak and defective study. Because this extensive degree of disagreement pervades all areas of science, debates about the merits or limitations of an individual study could often be endless, even when the topic is not controversial.
In light of the foregoing, it is useful to take a step back from many of the criticisms that have been directed at performance tests of personality. Rather than focus on the merits of individual studies or what remains to be known, it is valuable to recognize the broader patterns that are embedded in the research literature. Indeed, it is the purpose of systematically gathered meta-analytic data to clarify these broader patterns (Hunt, 1997).
What patterns can be discerned from the 184 meta-analytic findings in Tables 25.1, 25.2, and 25.3? A logical interpretation of these data is that the Rorschach and TAT have reasonable evidence supporting their reliability and validity. They are not noticeably deficient in their psychometric properties relative to other assessment procedures commonly used in psychology, psychiatry, and medicine.
Given this, it seems necessary for the arguments surrounding these tests to shift focus. Rather than criticizing individual studies or pointing out questions that have yet to be studied or resolved, it is necessary for those who argue these tests are flawed to systematically gather evidence that illustrates how this is so relative to other commonly used tests.
In the absence of such new evidence, the available scientific foundation indicates the Rorschach and TAT have reasonable psychometric properties. As such, while recognizing the limitations of all tests, clinicians should continue to employ these instruments as sources of information to be integrated with other findings in a sophisticated and differentiated psychological assessment. In addition, researchers should continue to focus on ways to refine individual scales for these tests and strive to provide an enhanced understanding of the construct measured by each scale. Efforts should also continue documenting the ways in which distinct testing methods can produce unique information about people. Patients who seek out clinical assessments and trust that psychologists will strive to fully understand their individual qualities and difficulties deserve no less.
APPENDIX: CITATIONS CONTRIBUTING DATA TO THE LARGER META-ANALYSES OF INTERRATER RELIABILITY CONDUCTED FOR THIS CHAPTER
The Rorschach Oral Dependency (ROD) Scale
The studies contributing scale-level intraclass correlations were Bornstein, Hilsenroth, Padawer, and Fowler (2000) and Fowler, Hilsenroth, and Nolan (2000). The studies that reported scale-level correlations were Bornstein (1998a); Bornstein, Bowers, and Bonner (1996a; four samples); Bornstein, Bowers, and Bonner (1996b); Bornstein, Bowers, and Robinson (1995); Bornstein and Greenberg (1991); Bornstein, Greenberg, Leone, and Galley (1990); Bornstein, Hill, Robinson, Calabrese, and Bowers (1996); Bornstein, Leone, and Galley (1988); Bornstein, Manning, Krukonis, Rossner, and Mastrosimone (1993); Bornstein and O’Neill (1997); Bornstein, O’Neill, Galley, Leone, and Castrianno (1988; two samples); Duberstein and Talbot (1992); Fowler, Hilsenroth, and Handler (1996); Gordon and Tegtmeyer (1983); Juni, Masling, and Brannon (1979; Spearman correlation); Levin and Masling (1995; r was estimated from the range reported for six findings); Masling, Weiss, and Rothschild (1968); Ruebush and Waite (1961; an early study of the construct); Russo, Cecero, and Bornstein (2001); and Wixom, Ludolph, and Westen (1993; results for practice scoring and the actual reliability sample were averaged).
The studies that reported both scale-level correlations and response-level kappa coefficients were Bornstein (1998b; two samples); Bornstein, Bonner, Kildow, and McCall (1997; two samples); Bornstein, Galley, and Leone (1986); Bornstein and Masling (1985); Bornstein and O’Neill (2000); Bornstein, Rossner, and Hill (1994; two samples); and Bornstein, Rossner, Hill, and Stepanian (1994; three samples). The studies that contributed just response-level kappa coefficients were Greenberg and Bornstein (1989; this study also reported r but because that result appeared to overlap with data reported in another study it was not used) and Narduzzi and Jackson (2000; the reliability N was confirmed by the first author). The studies that were excluded because they appeared to use overlapping reliability samples were Bornstein, Masling, and Poynton (1987); Bornstein, Poynton, and Masling (1985); Duberstein and Talbot (1993); O’Neill and Bornstein (1990); O’Neill and Bornstein (1991); and O’Neill and Bornstein (1996).
The Defense Mechanism Manual (DMM)
For the DMM, one study contributed both Pearson and intraclass correlations (Cramer, 1998b). Pearson correlations alone were obtained from Cramer (1987; reliability N was provided by the author and averaged across scales); Cramer (1998a); Cramer (2001); Cramer, Blatt, and Ford (1988); Cramer and Block (1998); Cramer and Brilliant (2001); Cramer and Gaul (1988; using total defense scores); Hibbard et al. (1994); Hibbard and Porcerelli (1998); Hibbard et al. (2000); and Porcerelli, Thomas, Hibbard, and Cogan (1998).
Four articles were excluded from the reliability analyses. Cramer (1995) only reported intrarater reliability (mean r ” .90, N ” 75). Cramer (1997a) did not report the reliability N and it was not readily available from the author’s files (r ” .91 for total defense use). Finally, the reliability samples in Cramer (1997b, 1999) appeared to be the same as those used in Cramer and Block (1998).
The Hamilton Depression Rating Scale (HDRS)
For HDRS reliability emerging from joint interviews or static sources of information (Table 25.1, Entry 7), scale-level correlations came from Akdemir et al. (2001); Bech, Bolwig, Kramp, and Rafaelsen (1979; Kendall’s W was treated as equivalent to Spearman r); Bech et al. (1975; Spearman r); Deluty, Deluty, and Carver (1986); Faravelli, Albanesi, and Poli (1986); Hamilton (1960); Knesevich, Biggs, Clayton, and Ziegler (1977; Spearman r); Kobak, Reynolds, Rosenfeld, and Greist (1990); Koenig, Pappas, Holsinger, and Bachar (1995); Montgomery and Asberg (1979; two samples); Potts et al. (1990); Rapp, Smith, and Britt (1990); Rehm and O’Hara (1985; median from two samples); Reynolds and Kobak (1995); Robins (1976); Snaith, Bridge, and Hamilton (1976); Wilson et al. (1966; results from six pairs of clinicians); and Ziegler, Meyer, Rosen, and Biggs (1978; Spearman r). Studies that contributed item-level correlations were Bech et al. (1975; Spearman r), Koenig et al. (1995), Rapp et al. (1990), Rehm and O’Hara (1985; median from two samples), and Ziegler et al. (1978; Spearman r).
Studies that contributed scale-level kappa/ICC values for the HDRS using joint interviews or static sources of information were Baer et al. (1995; two samples); Bech et al. (1997; using data reported for the Danish University Antidepressant Group [1993]); Danish University Antidepressant Group (1990); Demitrack, Faries, Herrera, DeBrota, and Potter (1998; only results from trained raters); Endicott, Cohen, Nee, Fleiss, and Sarantakos (1981); Faravelli et al. (1986; using only weighted kappa); Foster, Sclan, Welkowitz, Boksay, and Seeland (1988; two samples); Fuglum et al. (1996); Korner et al. (1990; using the average number of raters attending each interview); Maier, Philipp, et al. (1988, M results for 17- and 21-item scales); Mazure, Nelson, and Price (1986); Miller, Bishop, Norman, and Maddever (1985; two samples); Nair et al. (1995); O’Hara and Rehm (1983; two samples); Potts et al. (1990); Robbins, Alessi, Cook, Poznanski, and Yanchyshyn (1982); and Zheng et al. (1988). Studies that contributed item-level kappa/ICC values using joint interviews or static sources of information were Endicott et al. (1981; M results for the HDRS and extracted HDRS), Mazure et al. (1986), and Miller et al. (1985; two samples).
For HDRS separate interview designs (Table 25.1, Entry 17), studies that contributed scale-level correlations were Moras, Di Nardo, and Barlow (1992); Mundt et al. (1998); and Waldron and Bates (1965). The only study that contributed item-level correlations was Mundt et al. (1998). Studies that contributed scale-level kappa/ICC coefficients were Cicchetti and Prusoff (1983; two samples); Feldman-Naim, Myers, Clark, Turner, and Leibenluft (1997); Maier, Philipp, et al. (1988; two samples, M for 17- and 21-item scales); Miller et al. (1985); Moberg et al. (2001; two samples); and Williams (1988). Finally, studies that contributed item-level kappa/ICC values were Cicchetti and Prusoff (1983; two samples), Moberg et al. (2001; two samples), and Williams (1988).
The Hamilton Anxiety Rating Scale (HARS)
For HARS studies using a joint interview or static information design (Table 25.1, Entry 8), scale-level correlations came from Bech, Grosby, and Rafaelsen (1984; Spearman r); Deluty et al. (1986); Gjerris et al. (1983; Kendall’s W treated as equivalent to Spearman r; only data from experienced raters); Hamilton (1959; M of all pairwise reliabilities); Kobak, Reynolds, and Greist (1993; two samples); and Snaith et al. (1976). Studies that contributed scale-level kappa/ICC values were Baer et al. (1995; two samples); Bruss, Gruenberg, Goldstein, and Barber (1994); Clark and Donovan (1994); Maier, Buller, et al. (1988); and Shear et al. (2001; two samples). The studies that contributed item-level kappa/ICC values were Bruss et al. (1994); Clark and Donovan (1994); Maier, Buller, et al. (1988); and Shear et al. (2001; two samples).
For HARS studies using a separate interview design (Table 25.1, Entry 14), only Moras et al. (1992) contributed scale-level correlations. Scale-level kappa/ICC values came from Bruss et al. (1994) and Shear et al. (2001; two samples). Finally, studies that contributed item-level kappa/ICC coefficients were Bruss et al. (1994) and Shear et al. (2001).
Scientific Peer Review: Agreement Between Two Reviewers
For the reliability of peer reviewers, studies that contributed correlations for dimensional ratings of research quality were Bowen, Perloff, and Jacoby (1972; Kendall’s W was used for r); Eaton (1983; from raw data); Glover and Henkelman (1994; from raw data); Hargens and Herting (1990; three samples, from raw data); Hodgson (1995; two samples); Howard and Wilkinson (1998; from raw data); Kirk and Franke (1997); Marsh and Ball (1981; footnote 1 in Marsh & Ball, 1989, indicated that r and the ICC were identical in this sample); Marsh and Ball (1989); Marsh and Bazeley (1999); McReynolds (1971); Munley, Sharkin, and Gelso (1988; from raw data); Petty, Fleming, and Fabrigar (1999); Rothwell and Martyn (2000; two samples, from raw data); and Whitehurst (1984; three samples, from raw data).
The studies that contributed chance-corrected reliability statistics for dimensional ratings were Cicchetti (1991; 26 samples); Eaton (1983; from raw data); Fiske and Fogg (1990); Glover and Henkelman (1994; from raw data); Goodman, Berlin, Fletcher, and Fletcher (1994); Howard and Wilkinson (1998; from raw data); Kemper, McCarthy, and Cicchetti (1996; four samples); Kirk and Franke (1997; only results from two raters); Marsh and Ball (1981); Marsh and Ball (1989; footnote 1 indicated that r and the ICC were identical); Marsh and Bazeley (1999); Marusic, Mestrovic, Petrovecki, and Marusic (1998; M of two ratings); Munley et al. (1988); Plous and Herzog (2001); Plug (1993); Rothwell and Martyn (2000; four samples, two results from raw data); Rubin, Redelmeier, Wu, and Steinberg (1993; two samples); Scharschmidt, DeAmicis, Bacchetti, and Held (1994; from raw data); Strayhorn, McDermott, and Tanguay (1993; two samples, M of two ratings); Whitehurst (1984; using only the sample that did not overlap with Cicchetti, 1991); and Wiener et al. (1977).
The peer-reviewer studies that contributed chance-corrected statistics for dichotomous accept versus reject determinations were Cicchetti (1991; four samples), Eaton (1983), Hargens and Herting (1990; three samples, from raw data), Strayhorn et al. (1993; two samples), Varki (1994; from raw data, estimated N ” 727), and Whitehurst (1984; using two samples that did not overlap with Cicchetti, 1991; one result from raw data).
NOTES
- I appreciate the helpful input of S.P. Wong, Kenneth McGraw, and Robert Rosenthal on this issue. Robert Rosenthal also suggested considering weights derived from z scores computed across samples
for n and separately for judges (i.e., k, k(k ! 1)/2, or k ! 1). Because these weights would not directly quantify the number of objects rated or judgments rendered when summarizing results across studies, they were not used here.
Comparing reliability across disciplines is complicated because one cannot assume that the coefficients assembled here are a representative sample of findings from within these disciplines. However, if one computes mean values, they are consistent with the conclusion just stated in the text. For the Rorschach and TAT, average scale-level reliability was .85 (n ” 11) and average item-level reliability was .84 (n ” 3). The corresponding score and item-level averages were .67 (n ” 28) and .58 (n ” 14) for clinical determinations in psychology and psychiatry, .90 (n ” 5) and .61 (n ” 12) for medical variables, and .71 (n ” 1) and .41 (n ” 10) for nonclinical topics. Nonclinical topics consisted of Entries 24, 25, 36, 38, and 42 in Table 25.1. If one collapses across scales and items, the means are .85 for the Rorschach and TAT, .69 for medicine, .64 for clinical determinations in mental health, and .43 for nonclinical variables.
Several findings in Table 25.1 also address retest reliability. Specifically, interrater reliability studies that use a separate interview design provide evidence of short-term stability (see Table 25.1, Entries 14, 17, 29, and 30).
REFERENCES
- Achenbach, T.M., McConaughy, S.H., & Howell, C.T. (1987). Child/adolescent behavioral and emotional problems: Implications of cross-informant correlations for situational specificity. Psychological Bulletin, 101, 213–232.
- Ackerman, S.J., Clemence, A.J., Weatherill, R., & Hilsenroth, M.J. (1999). Use of the TAT in the assessment of DSM-IV Cluster B personality disorders. Journal of Personality Assessment, 73, 422–442.
- Ackerman, S.J., Hilsenroth, M.J., Clemence, A.J., Weatherill, R., & Fowler, J.C. (2000). The effects of social cognition and object representation on psychotherapy continuation. Bulletin of the Menninger Clinic, 64, 386–408.
- Acklin, M.W. (1999). Behavioral science foundations of the Rorschach test: Research and clinical applications. Assessment, 6, 319–326.
- Akdemir, A., Tuerkcapar, M.H., Orsel, S.D., Demirergi, N., Dag, I., & Ozbay, M.H. (2001). Reliability and validity of the Turkish version of the Hamilton Depression Rating Scale. Comprehensive Psychiatry, 42, 161–165.
- American Psychiatric Association. (1994). Diagnostic and statistical manual of mental disorders (4th ed.). Washington, DC: Author.
- Archer, J. (1999). Assessment of the reliability of the Conflict Tactics Scales: A meta-analytic review. Journal of Interpersonal Violence, 14, 1263–1289.
- Arkes, H.R. (1981). Impediments to accurate clinical judgment and possible ways to minimize their impact. Journal of Consulting and Clinical Psychology, 49, 323–330.
- Ascioglu, S., de Pauw, B.E., Donnelly, J.P., & Collette, L. (2001). Reliability of clinical research on invasive fungal infections: A systematic review of the literature. Medical Mycology, 39, 35–40.
- Ashton, R.H. (2000). A review and analysis of research on the testretest reliability of professional judgment. Journal of Behavioral Decision Making, 13, 277–294.
- Baer, L., Cukor, P., Jenike, M.A., Leahy, L., O’Laughlen, J., & Coyle, J.T. (1995). Pilot studies of telemedicine for patients with obsessive-compulsive disorder. American Journal of Psychiatry, 152, 1383–1385.
- Barends, A., Westen, D., Leigh, J., Silbert, D., & Byers, S. (1990). Assessing affect-tone of relationship paradigms from TAT and interview data. Psychological Assessment, 2, 329–332.
- Barton, M.B., Harris, R., & Fletcher, S.W. (1999). Does this patient have breast cancer? The screening clinical breast examination: Should it be done? How? Journal of the American Medical Association, 282, 1270–1280.
- Bech, P., Bolwig, T.G., Kramp, P., & Rafaelsen, O.J. (1979). The Bech-Rafaelsen Mania Scale and the Hamilton Depression Scale: Evaluation of homogeneity and inter-observer reliability. Acta Psychiatrica Scandinavica, 59, 420–430.
- Bech, P., Gram, L.F., Dein, E., Jacobsen, O., Vitger, J., & Bolwig, T.G. (1975). Quantitative rating of depressive states: Correlation between clinical assessment, Beck’s self-rating and Hamilton’s scale. Acta Psychiatrica Scandinavica, 51, 161–170.
- Bech, P., Grosby, H., & Rafaelsen, O.J. (1984). Generalized anxiety or depression measured by the Hamilton Anxiety Scale and the Melancholia Scale in patients before and after cardiac surgery. Psychopathology, 17, 253–263.
- Bech, P., Stage, K.B., Nair, N.P.V., Larsen, J.K., Kragh-Sorensen, P., & Gjerris, A. (1997). The Major Depression Rating Scale (MDS): Inter-rater reliability and validity across different settings in randomized moclobemide trials. Journal of Affective Disorders, 42, 39–48.
- Bornstein, R.F. (1996). Construct validity of the Rorschach Oral Dependency Scale: 1967–1995. Psychological Assessment, 8, 200–205.
- Bornstein, R.F. (1998a). Implicit and self-attributed dependency needs in dependent and histrionic personality disorders. Journal of Personality Assessment, 71, 1–14.
- Bornstein, R.F. (1998b). Implicit and self-attributed dependency strivings: Differential relationships to laboratory and field measures of help seeking. Journal of Personality and Social Psychology, 75, 778–787.
- Bornstein, R.F. (1998c). Interpersonal dependency and physical illness: A meta-analytic review of retrospective and prospective studies. Journal of Research in Personality, 32, 480–497.
- Bornstein, R.F. (1999). Criterion validity of objective and projective dependency tests: A meta-analytic assessment of behavioral prediction. Psychological Assessment, 11, 48–57.
- Bornstein, R.F., Bonner, S., Kildow, A.M., & McCall, C.A. (1997). Effects of individual versus group test administration on Rorschach Oral Dependency scores. Journal of Personality Assessment, 69, 215–228.
- Bornstein, R.F., Bowers, K.S., & Bonner, S. (1996a). Effects of induced mood states on objective and projective dependency scores. Journal of Personality Assessment, 67, 324–340.
- Bornstein, R.F., Bowers, K.S., & Bonner, S. (1996b). Relationships of objective and projective dependency scores to sex role orientation in college student participants. Journal of Personality Assessment, 66, 555–568.
- Bornstein, R.F., Bowers, K.S., & Robinson, K.J. (1995). Differential relationship of objective and projective dependency scores to self-reports of interpersonal life events in college student subjects. Journal of Personality Assessment, 65, 255–269.
- Bornstein, R.F., Galley, D.J., & Leone, D.R. (1986). Parental representations and orality. Journal of Personality Assessment, 50, 80–89.
- Bornstein, R.F., & Greenberg, R.P. (1991). Dependency and eating disorders in female psychiatric inpatients. Journal of Nervous and Mental Disease, 179, 148–152.
- Bornstein, R.F., Greenberg, R.P., Leone, D.R., & Galley, D.J. (1990). Defense mechanism correlates of orality. Journal of the American Academy of Psychoanalysis, 18, 654–666.
- Bornstein, R.F., Hill, E.L., Robinson, K.J., Calabrese, C., & Bowers, K.S. (1996). Internal reliability of Rorschach Oral Dependency Scale scores. Educational and Psychological Measurement, 56, 130–138.
- Bornstein, R.F., Hilsenroth, M.J., Padawer, J.R., & Fowler, J.C. (2000). Interpersonal dependency and personality pathology: Variations in Rorschach Oral Dependency scores across Axis II disorders. Journal of Personality Assessment, 75, 478–491.
- Bornstein, R.F., Leone, D.R., & Galley, D.J. (1988). Rorschach measures of oral dependence and the internalized selfrepresentation in normal college students. Journal of Personality Assessment, 52, 648–657.
- Bornstein, R.F., Manning, K.A., Krukonis, A.B., Rossner, S.C., & Mastrosimone, C.C. (1993). Sex differences in dependency: A comparison of objective and projective measures. Journal of Personality Assessment, 61, 169–181.
- Bornstein, R.F., & Masling, J. (1985). Orality and latency of volunteering to serve as experimental subjects: A replication. Journal of Personality Assessment, 49, 306–310.
- Bornstein, R.F., Masling, J., & Poynton, F.G. (1987). Orality as a factor in interpersonal yielding. Psychoanalytic Psychology, 4, 161–170.
- Bornstein, R.F., & O’Neill, R.M. (1997). Construct validity of the Rorschach Oral Dependency (ROD) Scale: Relationship of ROD
scores to WAIS-R scores in a psychiatric inpatient sample. Journal of Clinical Psychology, 53, 99–105.
- Bornstein, R.F., & O’Neill, R.M. (2000). Dependency and suicidality in psychiatric inpatients. Journal of Clinical Psychology, 56, 463–473.
- Bornstein, R.F., O’Neill, R.M., Galley, D.J., Leone, D.R., & Castrianno, L.M. (1988). Body image aberration and orality. Journal of Personality Disorders, 2, 315–322.
- Bornstein, R.F., Poynton, F.G., & Masling, J. (1985). Orality and depression: An empirical study. Psychoanalytic Psychology, 2, 241–249.
- Bornstein, R.F., Rossner, S.C., & Hill, E.L. (1994). Retest reliability of scores on objective and projective measures of dependency: Relationship to life events and intertest interval. Journal of Personality Assessment, 62, 398–415.
- Bornstein, R.F., Rossner, S.C., Hill, E.L., & Stepanian, M.L. (1994). Face validity and fakability of objective and projective measures of dependency. Journal of Personality Assessment, 63, 363–386.
- Borum, R., Otto, R., & Golding, S. (1993). Improving clinical judgment and decision making in forensic evaluation. Journal of Psychiatry and Law, 21, 35–76.
- Bowen, D.D., Perloff, R., & Jacoby, J. (1972). Improving manuscript evaluation procedures. American Psychologist, 27, 221– 225.
- Bruss, G.S., Gruenberg, A.M., Goldstein, R.D., & Barber, J.P. (1994). Hamilton Anxiety Rating Scale Interview Guide: Joint interview and test-retest methods for interrater reliability. Psychiatry Research, 53, 191–202.
- Callaham, M.L., Baxt, W.G., Waeckerle, J.F., & Wears, R.L. (1998). Reliability of editors’ subjective quality ratings of peer reviews of manuscripts. Journal of the American Medical Association, 280, 229–231.
- Capraro, M.M., Capraro, R.M., & Henson, R.K. (2001). Measurement error of scores on the Mathematics Anxiety Rating Scale across studies. Educational and Psychological Measurement, 61, 373–386.
- Cattell, R.B., & Vogelmann, S. (1977). A comprehensive trial of the scree and KG criteria for determining the number of factors. Multivariate Behavioral Research, 12, 289–325.
- Chalmers, T.C., & Lau, J. (1994). What is meta-analysis? Emergency Care Research Institute, 12, 1–5.
- Cicchetti, D.V. (1991). The reliability of peer review for manuscript and grant submissions: A cross-disciplinary investigation. Behavioral and Brain Sciences, 14, 119–186.
- Cicchetti, D.V. (1994). Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology. Psychological Assessment, 6, 284–290.
- Cicchetti, D.V., & Prusoff, B.A. (1983). Reliability of depression and associated clinical symptoms. Archives of General Psychiatry, 40, 987–990.
- Clark, D.B., & Donovan, J.E. (1994). Reliability and validity of the Hamilton Anxiety Rating Scale in an adolescent sample. Journal
of the American Academy of Child and Adolescent Psychiatry, 33, 354–360.
Conway, J.M., & Huffcutt, A.I. (1997). Psychometric properties of multisource performance ratings: A meta-analysis of subordinate, supervisor, peer, and self-ratings. Human Performance, 10, 331–360.
Conway, J.M., Jako, R.A., & Goodman, D.F. (1995). A metaanalysis of interrater and internal consistency reliability of selection interviews. Journal of Applied Psychology, 80, 565–579.
Cooper, G.D., Adams, H.B., & Gibby, R.G. (1969). Ego strength changes following perceptual deprivation: Report on a pilot study. Archives of General Psychiatry, 7, 213–217.
Cramer, P. (1987). The development of defense mechanisms. Journal of Personality, 55, 597–614.
Cramer, P. (1995). Identity, narcissism and defense mechanisms in late adolescence. Journal of Research in Personality, 29, 341–361.
Cramer, P. (1997a). Evidence for change in children’s use of defense mechanisms. Journal of Personality, 65, 233–247.
Cramer, P. (1997b). Identity, personality and defense mechanisms: An observer-based study. Journal of Research in Personality, 31, 58–77.
Cramer, P. (1998a). Freshman to senior year: A follow-up study of identity, narcissism and defense mechanisms. Journal of Research in Personality, 32, 156–172.
Cramer, P. (1998b). Threat to gender representation: Identity and identification. Journal of Personality, 66, 335–357.
Cramer, P. (1999). Personality, personality disorders, and defense mechanisms. Journal of Personality, 67, 535–554.
Cramer, P. (2001). Identification and its relation to identity development. Journal of Personality, 69, 667–688.
Cramer, P., Blatt, S.J., & Ford, R.Q. (1988). Defense mechanisms in the anaclitic and introjective personality configuration. Journal of Consulting and Clinical Psychology, 56, 610–616.
Cramer, P., & Block, J. (1998). Preschool antecedents of defense mechanism use in young adults: A longitudinal study. Journal of Personality and Social Psychology, 74, 159–169.
Cramer, P., & Brilliant, M.A. (2001). Defense use and defense understanding in children. Journal of Personality, 69, 297–322.
Cramer, P., & Gaul, R. (1988). The effects of success and failure on children’s use of defense mechanisms. Journal of Personality, 56, 729–742.
Crawford, C.B., & Koopman, P. (1979). Note: Inter-rater reliability of scree test and mean square ratio test of number of factors. Perceptual and Motor Skills, 49, 223–226.
Danish University Antidepressant Group. (1990). Paroxetine: A selective serotonin reuptake inhibitor showing better tolerance, but weaker antidepressant effect than clomipramine in a controlled multicenter study. Journal of Affective Disorders, 18, 289–299.
Danish University Antidepressant Group. (1993). Moclobemide: A reversible MAO-A inhibitor showing weaker antidepressant ef- fect than clomipramine in a controlled multicenter study. Journal of Affective Disorders, 28, 105–116.
Das, N.K., & Froehlich, L.A. (1985). Quantitative evaluation of peer review of program project and center applications in allergy and immunology. Journal of Clinical Immunology, 5, 220–227.
De Jonghe, B., Cook, D., Appere-De-Vecchi, C., Guyatt, G., Meade, M., & Outin, H. (2000). Using and understanding sedation scoring systems: A systematic review. Intensive Care Medicine, 26, 275–285.
De Kanter, R.J.A.M., Truin, G.J., Burgersdijk, R.C.W., van ’T Hof, M.A., Battistuzzi, P.G.F.C.M., Kalsbeek, H., et al. (1993). Prevalence in the Dutch adult population and a meta-analysis of signs and symptoms of temporomandibular disorder. Journal of Dental Research, 72, 1509–1518.
Deluty, B.M., Deluty, R.H., & Carver, C.S. (1986). Concordance between clinicians’ and patients’ ratings of anxiety and depression as mediated by private self-consciousness. Journal of Personality Assessment, 50, 93–106.
Demitrack, M.A., Faries, D., Herrera, J.M., DeBrota, D.J., & Potter, W.Z. (1998). The problem of measurement error in multisite clinical trials. Psychopharmacology Bulletin, 34, 19–24.
DeProspero, A., & Cohen, S. (1979). Inconsistent visual analysis of intrasubject data. Journal of Applied Behavior Analysis, 12, 573–579.
Dini, E.L., Holt, R.D., & Bedi, R. (1988). Comparison of two indices of caries patterns in 3–6 year old Brazilian children from areas with different fluoridation histories. International Dental Journal, 48, 378–385.
D’Olhaberriague, L., Litvan, I., Mitsias, P., & Mansbach, H.H. (1996). A reappraisal of reliability and validity studies in stroke. Stroke, 27, 2331–2336.
Duberstein, P.R., & Talbot, N.L. (1992). Parental idealization and the absence of Rorschach oral imagery. Journal of Personality Assessment, 59, 50–58.
Duberstein, P.R., & Talbot, N.L. (1993). Rorschach oral imagery, attachment style, and interpersonal relatedness. Journal of Personality Assessment, 61, 294–310.
Duhig, A.M., Renk, K., Epstein, M.K., & Phares, V. (2000). Interparental agreement on internalizing, externalizing, and total behavior problems: A meta-analysis. Clinical Psychology: Science and Practice, 7, 435–453.
Dworkin, S.F., LeResche, L., DeRouen, T., & Von Korff, M. (1990). Assessing clinical signs of temporomandibular disorders: Reliability of clinical examiners. Journal of Prosthetic Dentistry, 63, 574–579.
Eaton, W.O. (1983). Reliability of ethics reviews: Some initial empirical findings. Canadian Psychology, 24, 14–18.
Edinger, J.D., & Weiss, W.U. (1974). The relation between the altitude quotient and adjustment potential. Journal of Clinical Psychology, 30, 510–513.
Endicott, J., Cohen, J., Nee, J., Fleiss, J., & Sarantakos, S. (1981). Hamilton Depression Rating Scale: Extracted from regular and
change versions of the Schedule for Affective Disorders and Schizophrenia. Archives of General Psychiatry, 38, 98–103.
- Endicott, N.A., & Endicott, J. (1963). “Improvement” in untreated psychiatric patients. Archives of General Psychiatry, 9, 575–585.
- Etchells, E., Bell, C., & Robb, K. (1997). Does this patient have an abnormal systolic murmur? Journal of the American Medical Association, 277, 564–571.
- Exner, J.E., Jr. (1996). A comment on “The Comprehensive System for the Rorschach: A critical examination.” Psychological Science, 7, 11–13.
- Exner, J.E., Jr. (2001). A comment on “The misperception of psychopathology: Problems with norms of the Comprehensive System for the Rorschach.” Clinical Psychology: Science and Practice, 8, 386–396.
- Faravelli, C., Albanesi, G., & Poli, E. (1986). Assessment of depression: A comparison of rating scales. Journal of Affective Disorders, 11, 245–253.
- Fehlings, M.G., Rao, S.C., Tator, C.H., Skaf, G., Arnold, P., Benzel, E., et al. (1999). The optimal radiologic method for assessing spinal canal compromise and cord compression in patients with cervical spinal cord injury. Part II: Results of a multicenter study. Spine, 24, 605–613.
- Feldman-Naim, S., Myers, F.S., Clark, C.H., Turner, E.H., & Leibenluft, E. (1997). Agreement between face-to-face and telephone-administered mood ratings in patients with rapid cycling bipolar disorder. Psychiatry Research, 71, 129–132.
- Feurer, I.D., Becker, G.J., Picus, D., Ramirez, E., Darcy, M.D., & Hicks, M.E. (1994). Evaluating peer reviews: Pilot testing of a grading instrument. Journal of the American Medical Association, 272, 98–100.
- Fiske, D.W., & Fogg, L. (1990). But the reviewers are making different criticisms of my paper! Diversity and uniqueness in reviewer comments. American Psychologist, 45, 591–598.
- Foster, J.R., Sclan, S., Welkowitz, J., Boksay, I., & Seeland, I. (1988). Psychiatric assessment in medical long-term care facilities: Reliability of commonly used rating scales. International Journal of Geriatric Psychiatry, 3, 229–233.
- Fowler, J.C., Hilsenroth, M.J., & Handler, L. (1996). A multimethod approach to assessing dependency: The early memory dependency probe. Journal of Personality Assessment, 67, 399–413.
- Fowler, J.C., Hilsenroth, M.J., & Nolan, E. (2000). Exploring the inner world of self-mutilating borderline patients: A Rorschach investigation. Bulletin of the Menninger Clinic, 64, 365–385.
- Freedenfeld, R.N., Ornduff, S.R., & Kelsey, R.M. (1995). Object relations and physical abuse: A TAT analysis. Journal of Personality Assessment, 64, 552–568.
- Fuglum, E., Rosenberg, C., Damsbo, N., Stage, K., Lauritzen, L., & Bech, P. (1996). Screening and treating depressed patients. A comparison of two controlled citalopram trials across treatment settings: Hospitalized patients vs. patients treated by their family doctors. Danish University Antidepressant Group. Acta Psychiatrica Scandinavica, 94, 18–25.
- Garb, H.N. (1998). Studying the clinician: Judgment research and psychological assessment. Washington, DC: American Psychological Association.
- Garb, H.N. (1999). Call for a moratorium on the use of the Rorschach Inkblot test in clinical and forensic settings. Assessment, 6, 313–317.
- Garb, H.N., & Schramke, C.J. (1996). Judgment research and neuropsychological assessment: A narrative review and metaanalyses. Psychological Bulletin, 120, 140–153.
- Garfield, S.L. (2000). The Rorschach test in clinical diagnosis: A brief commentary. Journal of Clinical Psychology, 56, 431–434.
- Gibson, G., & Ottenbacher, K.J. (1988). Characteristics influencing the visual analysis of single-subject data: An empirical analysis. Journal of Applied Behavioral Science, 24, 298–314.
- Gjerris, A., Bech, P., Bojholm, S., Bolwig, T.G., Kramp, P., Clemmesen, L., et al. (1983). The Hamilton Anxiety Scale: Evaluation of homogeneity and inter-observer reliability in patients with depressive disorders. Journal of Affective Disorders, 5, 163–170.
- Glover, G.H., & Henkelman, R.M. (1994). Abstract scoring for the annual SMR program: Significance of reviewer score normalization. Magnetic Resonance Medicine, 32, 435–439.
- Goldfried, M.P., Stricker, G., & Weiner, I.B. (1971). Rorschach handbook of clinical and research applications. Englewood Cliffs, NJ: Prentice-Hall.
- Goldman, R.L. (1994). The reliability of peer assessments: A metaanalysis. Evaluation and the Health Professions, 17, 3–21.
- Goode, E. (2001, February 20). What’s in an Inkblot? Some say, not much. The New York Times, pp. D1, D4.
- Goodman, S.N., Berlin, J.A., Fletcher, S.W., & Fletcher, R.H. (1994). Manuscript quality before and after peer review and editing at Annals of Internal Medicine. Annals of Internal Medicine, 121, 11–21.
- Gordon, M., & Tegtmeyer, P.F. (1983). Oral-dependent content in children’s Rorschach protocols. Perceptual and Motor Skills, 57, 1163–1168.
- Gosling, S.D. (2001). From mice to men: What can we learn about personality from animal research? Psychological Bulletin, 127, 45–86.
- Gottfredson, S.D. (1978). Evaluating psychological research reports: Dimensions, reliability, and correlates of quality judgments. American Psychologist, 33, 920–934.
- Gottlieb, G.L., Gur, R.E., & Gur, R.C. (1988). Reliability of psychiatric scales in patients with dementia of the Alzheimer type. American Journal of Psychiatry, 145, 857–860.
- Greenberg, R.P., & Bornstein, R.F. (1989). Length of psychiatric hospitalization and oral dependency. Journal of Personality Disorders, 3, 199–204.
- Gross, C.R., Shinar, D., Mohr, J.P., Hier, D.B., Caplan, L.R., Price, T.R., et al. (1986). Interobserver agreement in the diagnosis of stroke type. Archives of Neurology, 43, 893–898.
- Grove, W.M., & Barden, R.C. (1999). Protecting the integrity of the legal system: The admissibility of testimony from mental health experts under Daubert/Kumho analyses. Psychology, Public Policy, and Law, 5, 224–242.
- Grueneich, R. (1992). The borderline personality disorder diagnosis: Reliability, diagnostic efficiency, and covariation with other personality disorder diagnoses. Journal of Personality Disorders, 6, 197–212.
- Hamilton, M. (1959). The assessment of anxiety states by rating. British Journal of Medical Psychology, 32, 50–55.
- Hamilton, M. (1960). A rating scale for depression. Journal of Neurology, Neurosurgery, and Psychiatry, 23, 56–62.
- Hammond, K.R. (1996). Human judgment and social policy: Irreducible uncertainty, inevitable error, unavoidable injustice. New York: Oxford University Press.
- Harbst, K.B., Ottenbacher, K.J., & Harris, S.R. (1991). Interrater reliability of therapists’ judgments of graphed data. Physical Therapy, 71, 107–115.
- Hargens, L.L., & Herting, J.R. (1990). A new approach to referees’ assessments of manuscripts. Social Science Research, 19, 1–16.
- Hathaway, A.P. (1982). Intelligence and non-intelligence factors contributing to scores on the Rorschach Prognostic Rating Scale. Journal of Personality Assessment, 46, 8–11.
- Hedlund, J.L., & Vieweg, B.W. (1979). The Hamilton Rating Scale for Depression: A comprehensive review. Journal of Operational Psychiatry, 10, 149–165.
- Hibbard, S., Farmer, L., Wells, C., Difillipo, E., Barry, W., Korman, R., et al. (1994). Validation of Cramer’s Defense Mechanism Manual for the TAT. Journal of Personality Assessment, 63, 197–210.
- Hibbard, S., Hilsenroth, M.J., Hibbard, J.K., & Nash, M.R. (1995). A validity study of two projective object representations measures. Psychological Assessment, 7, 432–439.
- Hibbard, S., & Porcerelli, J. (1998). Further validation of the Cramer Defense Mechanism Manual. Journal of Personality Assessment, 70, 460–483.
- Hibbard, S., Tang, P.C.Y., Latko, R., Park, J.H., Munn, S., Bolz, S., et al. (2000). Differential validity of the Defense Mechanism Manual for the TAT between Asian Americans and Whites. Journal of Personality Assessment, 75, 351–372.
- Hilsenroth, M.J., Fowler, J.C., Padawer, J.R., & Handler, L. (1997). Narcissism in the Rorschach revisited: Some reflections on empirical data. Psychological Assessment, 9, 113–121.
- Hodgson, C. (1995). Evaluation of cardiovascular grant-in-aid applications by peer review: Influence of internal and external reviewers and committees. Canadian Journal of Cardiology, 11, 864–868.
- Hodgson, C. (1997). How reliable is peer review? An examination of operating grant proposals simultaneously submitted to two similar peer review systems. Journal of Clinical Epidemiology, 50, 1189–1195.
- Holden, G.W., & Miller, P.C. (1999). Enduring and different: A meta-analysis of the similarity in parents’ child rearing. Psychological Bulletin, 125, 223–254.
- Holland, J.L., Johnston, J.A., & Asama, N.F. (1993). The Vocational Identity Scale: A diagnostic and treatment tool. Journal of Career Assessment, 1, 1–12.
- Howard, L., & Wilkinson, G. (1998). Peer review and editorial decision-making. British Journal of Psychiatry, 173, 110–113.
- Hunt, M. (1997). How science takes stock: The story of metaanalysis. New York: Russell Sage Foundation.
- Hunter, J.E., & Schmidt, F.L. (1990). Methods of meta-analysis: Correcting error and bias in research findings. Newbury Park, CA: Sage.
- Ismail, A.I., & Sohn, W. (1999). A systematic review of clinical diagnostic criteria of early childhood caries. Journal of Public Health Dentistry, 59, 171–191.
- Jones, D.B., Schlife, C.M., & Phipps, K.R. (1992). An oral health survey of Head Start children in Alaska: Oral health status, treatment needs, and cost of treatment. Journal of Public Health Dentistry, 52, 86–93.
- Juni, S., Masling, J., & Brannon, R. (1979). Interpersonal touching and orality. Journal of Personality Assessment, 43, 235–237.
- Justice, A.C., Berlin, J.A., Fletcher, S.W., Fletcher, R.H., & Goodman, S.N. (1994). Do readers and peer reviewers agree on manuscript quality? Journal of the American Medical Association, 272, 117– 119.
- Katz, L., Ripa, L.W., & Petersen, M. (1992). Nursing caries in Head Start children, St. Thomas, U.S. Virgin Islands: Assessed by examiners with different dental backgrounds. Journal of Clinical Pediatric Dentistry, 16, 124–128.
- Kemper, K.J., McCarthy, P.L., & Cicchetti, D.V. (1996). Improving participation and interrater agreement in scoring Ambulatory Pediatric Association abstracts: How well have we succeeded? Archives of Pediatrics and Adolescent Medicine, 150, 380–383.
- Kirk, S.A., & Franke, T.M. (1997). Agreeing to disagree: A study of the reliability of manuscript reviews. Social Work Research, 21, 121–126.
- Knesevich, J.W., Biggs, J.T., Clayton, P.J., & Ziegler, V.E. (1977). Validity of the Hamilton Rating Scale for Depression. British Journal of Psychiatry, 131, 49–52.
- Kobak, K.A., Reynolds, W.M., & Greist, J.H. (1993). Development and validation of a computer-administered version of the Hamilton Rating Scale. Psychological Assessment, 5, 487–492.
- Kobak, K.A., Reynolds, W.M., Rosenfeld, R., & Greist, J.H. (1990). Development and validation of a computer-administered version of the Hamilton Depression Rating Scale. Psychological Assessment, 2, 56–63.
- Koenig, H.G., Pappas, P., Holsinger, T., & Bachar, J.R. (1995). Assessing diagnostic approaches to depression in medically ill older adults: How reliably can mental health professionals make judgments about the cause of symptoms? Journal of the American Geriatrics Society, 43, 472–478.
- Korner, A., Nielsen, B.M., Eschen, F., Moller-Madsen, S., Stender, A., Christensen, E.M., et al. (1990). Quantifying depressive symptomatology: Inter-rater reliability and inter-item correlations. Journal of Affective Disorders, 20, 143–149.
- Lathrop, R.G., & Williams, J.E. (1987). The reliability of inverse scree tests for cluster analysis. Educational and Psychological Measurement, 47, 953–959.
- Leigh, J., Westen, D., Barends, A., Mendel, M.J., & Byers, S. (1992). The assessment of complexity of representations of people using TAT and interview data. Journal of Personality, 60, 809–837.
- Levin, R., & Masling, J. (1995). Relations of oral imagery to thought disorder in subject with frequent nightmares. Perceptual and Motor Skills, 80, 1115–1120.
- Lilienfeld, S.O., Wood, J.M., & Garb, H.N. (2000). The scientific status of projective techniques. Psychological Science in the Public Interest, 1, 27–66.
- Lilienfeld, S.O., Wood, J.M., & Garb, H.N. (2001, May). What’s wrong with this picture? Scientific American, 80–87.
- Livesley, J. (2000a). Introduction: Critical issues in the classification of personality disorder Part I. Journal of Personality Disorders, 14, 1–2.
- Livesley, J. (2000b). Introduction: Critical issues in the classification of personality disorder Part II. Journal of Personality Disorders, 14, 97–98.
- Loranger, A.W., Sartorius, N., Andreoli, A., Berger, P., Buchheim, P., Channabasavanna, S.M., et al. (1994). The International Personality Disorder Examination: The World Health Organization/ Alcohol, Drug Abuse, and Mental Health Administration international pilot study of personality disorders. Archives of General Psychiatry, 51, 215–224.
- Maier, W., Buller, R., Philipp, M., & Heuser, I. (1988). The Hamilton Anxiety Scale: Reliability, validity and sensitivity to change in anxiety and depressive disorders. Journal of Affective Disorders, 14, 61–68.
- Maier, W., Philipp, M., Heuser, I., Schlegel, S., Buller, R., & Wetzel, H. (1988). Improving depression severity assessment: I. Reliability, internal validity and sensitivity to change of three observer depression scales. Journal of Psychiatric Research, 22, 3–12.
- Marino, R.J., & Onetto, J.E. (1995). Caries experience in urban and rural Chilean 3-year-olds. Community Dentistry and Oral Epidemiology, 23, 60–61.
- Marsh, H.W., & Ball, S. (1981). Interjudgmental reliability of reviews for the Journal of Educational Psychology. Journal of Educational Psychology, 73, 872–880.
- Marsh, H.W., & Ball, S. (1989). The peer review process used to evaluate manuscripts submitted to academic journals: Interjudgmental reliability. Journal of Experimental Education, 57, 151–169.
- Marsh, H.W., & Bazeley, P. (1999). Multiple evaluations of grant proposals by independent assessors: Confirmatory factor analy-
sis evaluations of reliability, validity, and structure. Multivariate Behavioral Research, 34, 1–30.
- Martin, D.J., Garske, J.P., & Davis, M.K. (2000). Relation of the therapeutic alliance with outcome and other variables: A metaanalytic review. Journal of Consulting and Clinical Psychology, 68, 438–450.
- Marusic, A., Mestrovic, T., Petrovecki, M., & Marusic, M. (1998). Peer review in the Croatian Medical Journal from 1992–1996. Croatian Medical Journal, 39, 3–9.
- Masling, J., Weiss, L., & Rothschild, B. (1968). Relationships of oral imagery to yielding behavior and birth order. Journal of Consulting and Clinical Psychology, 32, 89–91.
- Matsuura, P., Waters, R.L., Adkins, R.H., Rothman, S., Gurbani, N., & Sie, I. (1989). Comparison of computerized tomography parameters of the cervical spin in normal control subjects and spinal cord-injured patients. Journal of Bone and Joint Surgery, 71-A, 183–188.
- Mazure, C., Nelson, J.C., & Price, L.H. (1986). Reliability and validity of the symptoms of major depressive illness. Archives of General Psychiatry, 43, 451–456.
- McGraw, K.O., & Wong, S.P. (1996). Forming inferences about some intraclass correlation coefficients. Psychological Methods, 1, 30–46.
- McKelvie, S.J. (1995). The VVIQ as a psychometric test of individual differences in visual imagery vividness: A critical quantitative review and plea for direction. Journal of Mental Imagery, 19, 1–106.
- McReynolds, P. (1971). Reliability of ratings of research papers. American Psychologist, 26, 400–401.
- Meyer, G.J. (1997). Assessing reliability: Critical corrections for a critical examination of the Rorschach Comprehensive System. Psychological Assessment, 9, 480–489.
- Meyer, G.J. (Ed.). (1999). Special Section I: The utility of the Rorschach for clinical assessment. Psychological Assessment, 11, 235–302.
- Meyer, G.J. (2000). The incremental validity of the Rorschach Prognostic Rating Scale over the MMPI Ego Strength Scale and IQ. Journal of Personality Assessment, 74, 356–370.
- Meyer, G.J. (2001a). Evidence to correct misperceptions about Rorschach norms. Clinical Psychology: Science and Practice, 8, 389–396.
- Meyer, G.J. (Ed.). (2001b). Special Section II: The utility of the Rorschach for clinical assessment II. Psychological Assessment, 13, 419–502.
- Meyer, G.J. (2002). Exploring possible ethnic differences and bias in the Rorschach Comprehensive System. Journal of Personality Assessment, 78, 104–129.
- Meyer, G.J., & Archer, R.P. (2001). The hard science of Rorschach research: What do we know and where do we go? Psychological Assessment, 13, 486–502.
- Meyer, G.J., Baxter, D., Exner, J.E., Jr., Fowler, J.C., Hilsenroth, M.J., Piers, C.C., et al. (2002). An examination of interrater re-
liability for scoring the Rorschach Comprehensive System in eight data sets. Journal of Personality Assessment, 78, 219–274.
- Meyer, G.J., Finn, S.E., Eyde, L., Kay, G.G., Moreland, K.L., Dies, R.R., et al. (2001). Psychological testing and psychological assessment: A review of evidence and issues. American Psychologist, 56, 128–165.
- Meyer, G.J., & Handler, L. (1997). The ability of the Rorschach to predict subsequent outcome: A meta-analysis of the Rorschach Prognostic Rating Scale. Journal of Personality Assessment, 69, 1–38.
- Miller, I.W., Bishop, S.B., Norman, W.H., & Maddever, H. (1985). The Modified Hamilton Rating Scale for Depression: Reliability and validity. Psychiatry Research, 14, 131–142.
- Moberg, P.J., Lazarus, L.W., Mesholam, R.I., Bilker, W., Chuy, I.L., Neyman, I., et al. (2001). Comparison of the standard and structured interview guide for the Hamilton Depression Rating Scale in depressed geriatric inpatients. American Journal of Geriatric Psychiatry, 9, 35–40.
- Montgomery, S.A., & Asberg, M. (1979). A new depression scale designed to be sensitive to change. British Journal of Psychiatry, 134, 382–389.
- Moras, K., Di Nardo, P.A., & Barlow, D.H. (1992). Distinguishing anxiety and depression: Reexamination of the reconstructed Hamilton scales. Psychological Assessment, 4, 224–227.
- Mundt, J.C., Kobak, K.A., Taylor, L.V., Mantle, J.M., Jefferson, J.W., Katzelnick, D.J., et al. (1998). Administration of the Hamilton Depression Rating Scale using interactive voice response technology. MD Computing, 15, 31–39.
- Munley, P.H., Sharkin, B.S., & Gelso, C.J. (1988). Reviewer ratings and agreement on manuscripts reviewed for the Journal of Counseling Psychology. Journal of Counseling Psychology, 35, 198– 202.
- Myers, K.A., & Farquhar, D.R. (2001). Does this patient have clubbing? Journal of the American Medical Association, 286, 341– 347.
- Nair, N.P.V., Amin, M., Holm, P., Katona, C., Klitgaard, N., Ng-Ying-Kin, N.M.K., et al. (1995). Moclobemide and nortriptyline in elderly depressed patients: A randomized, multicenter trial against placebo. Journal of Affective Disorders, 33, 1–9.
- Narduzzi, K.J., & Jackson, T. (2000). Personality differences between eating-disordered women and a nonclinical comparison sample: A discriminant classification analysis. Journal of Clinical Psychology, 56, 699–710.
- Newmark, C.S., Finkelstein, M., & Frerking, R.A. (1974). Comparison of the predictive validity of two measures of psychotherapy prognosis. Journal of Personality Assessment, 38, 144–148.
- Newmark, C.S., Hetzel, W., Walker, L., Holstein, S., & Finkelstein, M. (1973). Predictive validity of the Rorschach Prognostic Rating Scale with behavior modification techniques. Journal of Clinical Psychology, 29, 246–248.
- Newmark, C.S., Konanc, J.T., Simpson, M., Boren, R.B., & Prillaman, K. (1979). Predictive validity of the Rorschach Prog-nostic Rating Scale with schizophrenic patients. Journal of Nervous and Mental Disease, 167, 135–143.
- Nwosu, C.R., Khan, K.S., Chien, P.F.W., & Honest, M.R. (1998). Is real-time ultrasonic bladder volume estimation reliable and valid? A systematic overview. Scandinavian Journal of Urology and Nephrology, 32, 325–330.
- O’Hara, M.W., & Rehm, L.P. (1983). Hamilton Rating Scale for Depression: Reliability and validity of judgments of novice raters. Journal of Consulting and Clinical Psychology, 51, 318–319.
- Okada, Y., Ikata, T., & Katoh, S. (1994). Morphologic analysis of the cervical spinal cord, dural tube, and spinal canal by magnetic resonance imaging in normal adults and patients with cervical spondylotic myelopathy. Spine, 19, 2331–2335.
- O’Neill, R.M., & Bornstein, R.F. (1990). Oral-dependence and gender: Factors in help-seeking response set and self-reported psychopathology in psychiatric inpatients. Journal of Personality Assessment, 55, 28–40.
- O’Neill, R.M., & Bornstein, R.F. (1991). Orality and depression in psychiatric inpatients. Journal of Personality Disorders, 5, 1–7.
- O’Neill, R.M., & Bornstein, R.F. (1996). Dependency and alexithymia in psychiatric inpatients. Journal of Nervous and Mental Disease, 184, 302–306.
- Ornduff, S.R., Freedenfeld, R.N., Kelsey, R.M., & Critelli, J.W. (1994). Object relations of sexually abused female subjects: A TAT analysis. Journal of Personality Assessment, 63, 223–238.
- Ornduff, S.R., & Kelsey, R.M. (1996). Object relations of sexually and physically abused female children: A TAT analysis. Journal of Personality Assessment, 66, 91–105.
- O’Sullivan, D.M., & Tinanoff, N. (1996). The association of early dental caries patterns with caries incidence in preschool children. Journal of Public Health Dentistry, 56, 81–83.
- Ottenbacher, K.J. (1986). Reliability and accuracy of visually analyzing graphed data from single-subject designs. American Journal of Occupational Therapy, 40, 464–469.
- Ottenbacher, K.J. (1993). Interrater agreement of visual analysis in single-subject decisions: Quantitative review and analysis. American Journal on Mental Retardation, 98, 135–142.
- Ottenbacher, K.J., & Cusik, A. (1991). An empirical investigation of interrater agreement for single-subject data using graphs with and without trend lines. Journal of the Association for Persons with Severe Handicaps, 16, 48–55.
- Ottenbacher, K.J., Hsu, Y., Granger, C.V., & Fiedler, R.C. (1996). The reliability of the Functional Independence Measure: A quantitative review. Archives of Physical Medicine and Rehabilitation, 77, 1226–1232.
- Park, H.-S., Marascuilo, L., & Gaylord-Ross, R. (1990). Visual inspection and statistical analysis in single-case designs. Journal of Experimental Education, 58, 311–320.
- Parker, K.C.H., Hanson, R.K., & Hunsley, J. (1988). MMPI, Rorschach, and WAIS: A meta-analytic comparison of reliability, stability, and validity. Psychological Bulletin, 103, 367–373.
- Paunio, P., Rautava, P., Helenius, H., Alanen, P., & Sillanpa¨a¨, M. (1993). The Finnish Family Competence Study: The relationship between caries, dental health habits and general health in 3-yearold Finnish children. Caries Research, 27, 154–160.
- Petty, R.E., Fleming, M.A., & Fabrigar, L.R. (1999). The review process at PSPB: Correlates of interreviewer agreement and manuscript acceptance. Personality and Social Psychology Bulletin, 25, 188–203.
- Plous, S., & Herzog, H. (2001). Reliability of protocol reviews for animal research. Science, 293, 608–609.
- Plug, C. (1993). The reliability of manuscript evaluation for the South African Journal of Psychology. South African Journal of Psychology, 23, 43–48.
- Porcerelli, J.H., Thomas, S., Hibbard, S., & Cogan, R. (1998). Defense mechanisms development in children, adolescents, and late adolescents. Journal of Personality Assessment, 71, 411–420.
- Potts, M.K., Daniels, M., Burnam, M.A., & Wells, K.B. (1990). A structured interview version of the Hamilton Depression Rating Scale: Evidence of reliability and versatility of administration. Journal of Psychiatric Research, 24, 335–350.
- Ramsay, I.N., Mathers, A.M., Hood, V.D., & Torbet, T.E. (1991). Ultrasonic assessment of residual bladder volume: A quick, simple and accurate bedside assessment. Obstetrics and Gynecology Today, 2, 68–70.
- Rao, S.C., & Fehlings, M.G. (1999). The optimal radiologic method for assessing spinal canal compromise and cord compression in patients with cervical spinal cord injury. Part I: An evidencebased analysis of the published literature. Spine, 24, 598–604.
- Rapp, S.R., Smith, S.S., & Britt, M. (1990). Identifying comorbid depression in elderly medical patients: Use of the Extracted Hamilton Depression Rating Scale. Psychological Assessment, 2, 243–247.
- Rehm, L.P., & O’Hara, M.W. (1985). Item characteristics of the Hamilton Rating Scale for Depression. Journal of Psychiatric Research, 19, 31–41.
- Reynolds, W.M., & Kobak, K.A. (1995). Reliability and validity of the Hamilton Depression Inventory: A paper-and-pencil version of the Hamilton Depression Rating Scale clinical interview. Psychological Assessment, 7, 472–483.
- Ritzler, B., Erard, R., & Pettigrew, G. (2002). Protecting the integrity of Rorschach expert witnesses: A reply to Grove and Barden (1999) re: the admissibility of testimony under Daubert/Kumho analyses. Psychology, Public Policy, and Law, 8, 201–215.
- Robbins, D.R., Alessi, N.E., Cook, S.C., Poznanski, E.O., & Yanchyshyn, G.W. (1982). The use of the Research Diagnostic Criteria (RDC) for depression in adolescent psychiatric inpatients. Journal of the American Academy of Child Psychiatry, 21, 251–255.
- Roberts, B.W., & DelVecchio, W.F. (2000). The rank-order consistency of personality traits from childhood to old age: A quantitative review of longitudinal studies. Psychological Bulletin, 126, 3–25.
- Robins, A.H. (1976). Depression in patients with Parkinsonism. British Journal of Psychiatry, 128, 141–145.
- Ronan, G.F., Colavito, V.A., & Hammontree, S.R. (1993). Personal Problem-Solving System for scoring TAT responses: Preliminary validity and reliability data. Journal of Personality Assessment, 61, 28–40.
- Ronan, G.F., Date, A.L., & Weisbrod, M. (1995). Personal Problem-Solving Scoring of the TAT: Sensitivity to training. Journal of Personality Assessment, 64, 119–131.
- Ronan, G.F., Senn, J., Date, A., Maurer, L., House, K., Carroll, J., et al. (1996). Personal Problem-Solving Scoring of TAT responses: Known-groups validation. Journal of Personality Assessment, 67, 641–653.
- Rosenthal, R. (1991). Meta-analytic procedures for social research (Rev. ed.). Newbury Park, CA: Sage.
- Rothstein, H.R. (1990). Interrater reliability of job performance ratings: Growth to asymptote level with increasing opportunity to observe. Journal of Applied Psychology, 75, 322–327.
- Rothwell, P.M., & Martyn, C.N. (2000). Reproducibility of peer review in clinical neuroscience. Is agreement between reviewers any greater than would be expected by chance alone? Brain, 123 (Pt 9), 1964–1969.
- Rubin, H.R., Redelmeier, D.A., Wu, A.W., & Steinberg, E.P. (1993). How reliable is peer review of scientific abstracts? Looking back at the 1991 Annual Meeting of the Society of General Internal Medicine. Journal of General Internal Medicine, 8, 255–258.
- Ruebush, B.K., & Waite, R.R. (1961). Oral dependency in anxious and defensive children. Merrill-Palmer Quarterly, 7, 181–190.
- Russell, A.S., Thorn, B.D., & Grace, M. (1983). Peer review: A simplified approach. Journal of Rheumatology, 10, 479–481.
- Russo, P.M., Cecero, J.J., & Bornstein, R.F. (2001). Implicit and self-attributed dependency needs in homeless men and women. Journal of Social Distress and the Homeless, 10, 269–277.
- Salgado, J.F., & Moscoso, S. (1996). Meta-analysis of interrater reliability of job performance ratings in validity studies of personnel selection. Perceptual and Motor Skills, 83, 1195–1201.
- Scharschmidt, B.F., DeAmicis, A., Bacchetti, P., & Held, M.J. (1994). Chance, concurrence, and clustering: Analysis of reviewers’ recommendations on 1,000 submissions to The Journal of Clinical Investigation. Journal of Clinical Investigation, 93, 1877–1880.
- Schuerger, J.M., & Witt, A.C. (1989). The temporal stability of individually tested intelligence. Journal of Clinical Psychology, 45, 294–302.
- Scullen, S.E. (1997). When ratings from one source have been averaged, but ratings from another source have not: Problems and solutions. Journal of Applied Psychology, 82, 880–888.
- Segal, D.L., Hersen, M., & Van Hasselt, V.B. (1994). Reliability of the Structured Clinical Interview for DSM-III-R: An evaluative review. Comprehensive Psychiatry, 35, 316–327.
- Shear, M.K., Vander Bilt, J., Rucci, P., Endicott, J., Lydiard, B., Otto, M.W., et al. (2001). Reliability and validity of a structured
interview guide for the Hamilton Anxiety Rating Scale (SIGH-A). Depression and Anxiety, 13, 166–178.
- Shulman, K.I. (2000). Clock-drawing: Is it the ideal cognitive screening test? International Journal of Geriatric Psychiatry, 15, 548–561.
- Snaith, R.P., Bridge, G.W.K., & Hamilton, M. (1976). The Leeds Scales for the Self-Assessment of Anxiety and Depression. British Journal of Psychiatry, 128, 156–163.
- Spengler, P.M., Strohmer, D.C., Dixon, D.N., & Shivy, V.A. (1995). A scientist-practitioner model of psychological assessment: Implications for training, practice and research. The Counseling Psychologist, 23, 506–534.
- Steinberg, M. (2000). Advances in the clinical assessment of dissociation: The SCID-D-R. Bulletin of the Menninger Clinic, 64, 146–163.
- Strayhorn, J., McDermott, J.F., & Tanguay, P.E. (1993). An intervention to improve the reliability of manuscript reviews for the Journal of the American Academy of Child and Adolescent Psychiatry. American Journal of Psychiatry, 150, 947–952.
- Streiner, D.L. (1998). Factors affecting reliability of interpretations of scree plots. Psychological Reports, 83, 687–694.
- Stukenberg, K.W., Dura, J.R., & Kielcolt-Glaser, J.K. (1990). Depression screening scale validation in an elderly, community dwelling population. Psychological Assessment, 2, 134–138.
- Swain, A., & Suls, J. (1996). Reproducibility of blood pressure and heart rate reactivity: A meta-analysis. Psychophysiology, 33, 162–174.
- Szatmari, P. (2000). The classification of autism, Asperger’s syndrome, and pervasive developmental disorder. Canadian Journal of Psychiatry, 45, 731–738.
- van Ijzendoorn, M.H., Schuengel, C., & Bakermans-Kranenburg, M.J. (1999). Disorganized attachment in early childhood: Metaanalysis of precursors, concomitants, and sequelae. Development and Psychopathology, 11, 225–249.
- van Rooyen, S., Black, N., & Godlee, F. (1999). Development of the review quality instrument (RQI) for assessing peer reviews of manuscripts. Journal of Clinical Epidemiology, 52, 625–629.
- van Rooyen, S., Godlee, F., Evans, S., Black, N., & Smith, R. (1999). Effect of open peer review on quality of reviews and on reviewers’ recommendations: A randomised trial. British Medical Journal, 318, 23–27.
- Varki, A.P. (1994). The screening review system: Fair or foul? Journal of Clinical Investigation, 93, 1871–1874.
- Viswesvaran, C., & Ones, D.S. (2000). Measurement error in “Big Five factors” personality assessment: Reliability generalization across studies and measures. Educational and Psychological Measurement, 60, 224–235.
- Viswesvaran, C., Ones, D.S., & Schmidt, F.L. (1996). Comparative analysis of the reliability of job performance ratings. Journal of Applied Psychology, 81, 557–574.
- Waldron, J., & Bates, T.J.N. (1965). The management of depression in hospital: A comparative trial of desipramine and imipramine. British Journal of Psychiatry, 111, 511–516.
- Walsh, E., Rooney, M., Appleby, L., & Wilkinson, G. (2000). Open peer review: A randomised controlled trial. British Journal of Psychiatry, 176, 47–51.
- Weathers, F.W., Keane, T.M., & Davidson, J.R. (2001). Clinicianadministered PTSD scale: A review of the first ten years of research. Depression and Anxiety, 13, 132–156.
- Weiner, I.B. (2000). Using the Rorschach properly in practice and research. Journal of Clinical Psychology, 56, 435–438.
- Westen, D., Huebner, D., Lifton, N., Silverman, M., & Boekamp, J. (1991). Assessing complexity of representations of people and understanding of social causality: A comparison of natural science and clinical psychology graduate students. Journal of Social and Clinical Psychology, 10, 448–458.
- Westen, D., Klepser, J., Ruffins, S.A., Silverman, M., Lifton, N., & Boekamp, J. (1991). Object relations in childhood and adolescence: The development of working representations. Journal of Consulting and Clinical Psychology, 59, 400–409.
- Westen, D., Lohr, N., Silk, K.R., Gold, L., & Kerber, K. (1990). Object relations and social cognition in borderlines, major depressives, and normals: A Thematic Apperception Test analysis. Psychological Assessment, 2, 355–364.
- Westen, D., Ludolph, P., Block, M.J., Wixom, J., & Wiss, F.C. (1990). Developmental history and object relations in psychiatrically disturbed adolescent girls. American Journal of Psychiatry, 147, 1061–1068.
- Westen, D., Ludolph, P., Lerner, H., Ruffins, S., & Wiss, F.C. (1990). Object relations in borderline adolescents. Journal of the American Academy of Child and Adolescent Psychiatry, 29, 338–348.
- Westen, D., Ludolph, P., Silk, K.R., Kellam, A., Gold, L., & Lohr, N. (1990). Object relations in borderline adolescents and adults: Developmental differences. Adolescent Psychiatry, 17, 360– 384.
- Whisman, M.A., Strosahl, K., Fruzzetti, A.E., Schmaling, K.B., Jacobson, N.S., & Miller, D.M. (1989). A structured interview version of the Hamilton Rating Scale for Depression: Reliability and validity. Psychological Assessment, 1, 238–241.
- Whitehurst, G.J. (1984). Interrater agreement for journal manuscript reviews. American Psychologist, 39, 22–28.
- Wiener, S.L., Urivetzky, M., Bregman, D., Cohen, J., Eich, R., Gootman, N., et al. (1977). Peer review: Inter-reviewer agreement during evaluation of research grant applications. Clinical Research, 25, 306–311.
- Williams, G.J., Monder, R., & Rychlak, J.F. (1967). A one-year concurrent validity study of the Rorschach Prognostic Rating Scale. Journal of Projective Techniques and Personality Assessment, 31, 30–33.
- Williams, J.B. (1988). A structured interview guide for the Hamilton Depression Rating Scale. Archives of General Psychiatry, 45, 742–747.
- Wilson, I.C., Rabon, A.M., Merrick, H.A., Knox, A.E., Taylor, J.P., & Buffaloe, W.J. (1966). Imipramine pamoate in the treatment of depression. Psychosomatics, 7, 251–253.
- Wixom, J., Ludolph, P., & Westen, D. (1993). The quality of depression in adolescents with borderline personality disorder. Journal of the American Academy of Child and Adolescent Psychiatry, 32, 1172–1177.
- Wood, J.M., Lilienfeld, S.O., Garb, H.N., & Nezworski, M.T. (2000). The Rorschach test in clinical diagnosis: A critical review, with a backward look at Garfield (1947). Journal of Clinical Psychology, 56, 395–430.
- Wood, J.M., Nezworski, M.T., Garb, H.N., & Lilienfeld, S.O. (2001). The misperception of psychopathology: Problems with the norms of the Comprehensive System for the Rorschach. Clinical Psychology: Science and Practice, 8, 350–373.
- Wood, J.M., Nezworski, M.T., & Stejskal, W.J. (1996). The Comprehensive System for the Rorschach: A critical examination. Psychological Science, 7, 3–10.
- Yagot, K., Nazhat, N.Y., & Kuder, S.A. (1990). Prolonged nursinghabit caries index. Journal of the International Association of Dentistry for Children, 20, 8–10.
- Yarnold, P.R., & Mueser, K.T. (1989). Meta-analyses of the reliability of Type A behaviour measures. British Journal of Medical Psychology, 62, 43–50.
- Zheng, Y., Zhao, J., Phillips, M., Liu, J., Cai, M., Sun, S., et al. (1988). Validity and reliability of the Chinese Hamilton Depression Rating Scale. British Journal of Psychiatry, 152, 660–664.
- Ziegler, V.E., Meyer, D.A., Rosen, S.H., & Biggs, J.T. (1978). Reliability of video taped Hamilton ratings. Biological Psychiatry, 13, 119–122.
- Zimmerman, M. (1994). Diagnosing personality disorders: A review of issues and research methods. Archives of General Psychiatry, 51, 225–245.